
文章目录
- ********** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ******************** ***************** 场景 自动驾驶 / AR 语音信号 流视频 GPU 渲染 科学、云计算 内存缩减 科学应用 医学图像 数据库服务器 人工智能图像 文本传输 GAN媒体压缩 图像压缩 文件同步 数据库系统 技术 点云压缩 稀疏快速傅里叶变换 有损视频压缩 网格压缩 动态选择压缩算法框架 无损压缩 分层数据压缩 医学图像压缩 无损通用压缩 人工智能图像压缩 短字符串压缩 GAN 压缩的在线多粒度蒸馏 图像压缩 文件传输压缩 快速随机访问字符串压缩 开源项目 Draco / 基于深度学习算法/PCL/OctNet SFFT AV1 / H.266编码 / H.266解码/VP9 MeshOpt / Draco Ares LZ4 HCompress DICOM Brotli RAISR AIMCS OMGD OpenJPEG rsync FSST
-
- FPZIP 使用洛伦兹预测器利用标量 n 维网格内点的直接邻域的平滑性,使用范围编码器压缩小的残值。该方案具有很高的压缩效率,特别是对于单精度值。
- FPC 使用一对基于哈希表的值预测器来压缩非结构化双精度数据流。它提供了一个可调参数,利用压缩效率提高速度。线程并行的pFPC 变体允许通过以块的形式处理输入数据来进一步确定压缩吞吐量的优先级。
- SPDP 结合了一维预测和LZ77变体,可以压缩单精度和双精度数据,而不需要对任何一种格式进行专门处理。
- MPC 是一种用于GPU 的快速压缩方案。将一个简单的一维值预测器与一个位重组方案相结合,可以很好地映射到目标硬件的残差中去零位。
- APE 和ACE 压缩器自适应地从多个值预测器中选择,将 n 维网格中的数据点与其已处理过的邻居解相关。残差使用一种变体的Golomb 编码进行压缩。
- 数值预测科学浮点数据中的单个数值通常在低阶尾数位表现出较高的熵,尾数也很少出现精确到重复,这降低了传统字典编码器的效率。相反,我们可以使用专门的方法对已经处理过的数据进行预测,只对残差进行编码。 SPDP 和MPC 使用简单的固定步长值预测器,通过存储 k 个值,并用最近编码的第 k 个值预测每个点。 FPC 和pFPC 使用一对基于哈希表的预测器来维护一个较大的内部状态,以利用值和值增量中的重复模式。 fpzip 使用浮点洛伦兹预测器来估计 n 维空间中长度为 2 的超立方体的一个角的值。fpzip通过奇数条边可到达的所有其他角加起来,然后减去通过偶数条边可到达的角。当超立方体可用n - 1次隐式多项式表达时,预测精度是精确的。 APE 和 ACE 扩展了fpzip预测器的思想,通过在每个维度上使用高维多项式,以更大的计算成本为代价提高了预测精度。
- 在无损压缩环境中,浮点减法不适合用来计算预测残差。小幅度的浮点值通常不会以简短的、可压缩的位的形式出现,而且浮点数的有限精度使浮点减法成为一种非双射的运算。因此,所有研究的算法都明确地计算位表示的残差。 FPC和pFPC 使用逐位异或差,而SPDP和MPC 将操作数位重新解释为整数,并对整数减法的结果进行编码。 APE和ACE 提供了两种变体。 fpzip 也使用整数减法,但是它根据符号位对操作数进行反运算,以提高映射的连续性。
- 精确的预测会产生具有许多相同前导位的小幅度残差,即异或运算符为零以及二进制补码的整数减法的冗余符号位。对这些前导位进行有效编码是大多数研究方案中所采用的数据简化机制。 fpzip 使用一个范围编码器来压缩前导冗余位的数量,紧接着复制剩余位。距离编码器能够产生的接近最佳的位串使得其非常节省空间。然而,所需的位粒度寻址难的问题难以有效解决。 APE 和ACE 使用与fpzip类似的方法,但使用符号排序的Golomb 代码来编码冗余位的数量。 FPC 和 pFPC 通过计算双精度残差中前导零字节的数量,使用固定映射对运行长度和4 bit中的预测部分进行编码。剩余部分将从第一个非零字节开始逐字输出。这种方法是无状态的,在不可压缩的情况下有可接受的1/16开销,代价是由于粒度较低而浪费比特。 MPC 将剩余流分成 32 个单精度(或 64 个双精度)值的块,发出 32(64)个最高有效位,然后是 32(64)个第二最高有效位,依此类推。零字将从输出流中删除,并在每个编码所有非零字位置的块上替换为32或64位掩码。这种方法在不可压缩的情况下有非常低的开销,仅仅为1/32(1/64),由于字符粒度寻址,该方法在 GPU 上得到了有效的实现,但需要块内所有的残差具有相似的位宽才能实现。 SPDP 从一个类似于 MPC 的重组策略开始,但是SPDP是在字节级别上的重组策略。SPDP接着使用字节粒度整数减差运算,并使用 lz77 系列编码器对结果流进行编码。这可以消除除前导零之外的重复模式,并使 SPDP 也能处理非浮点数据。
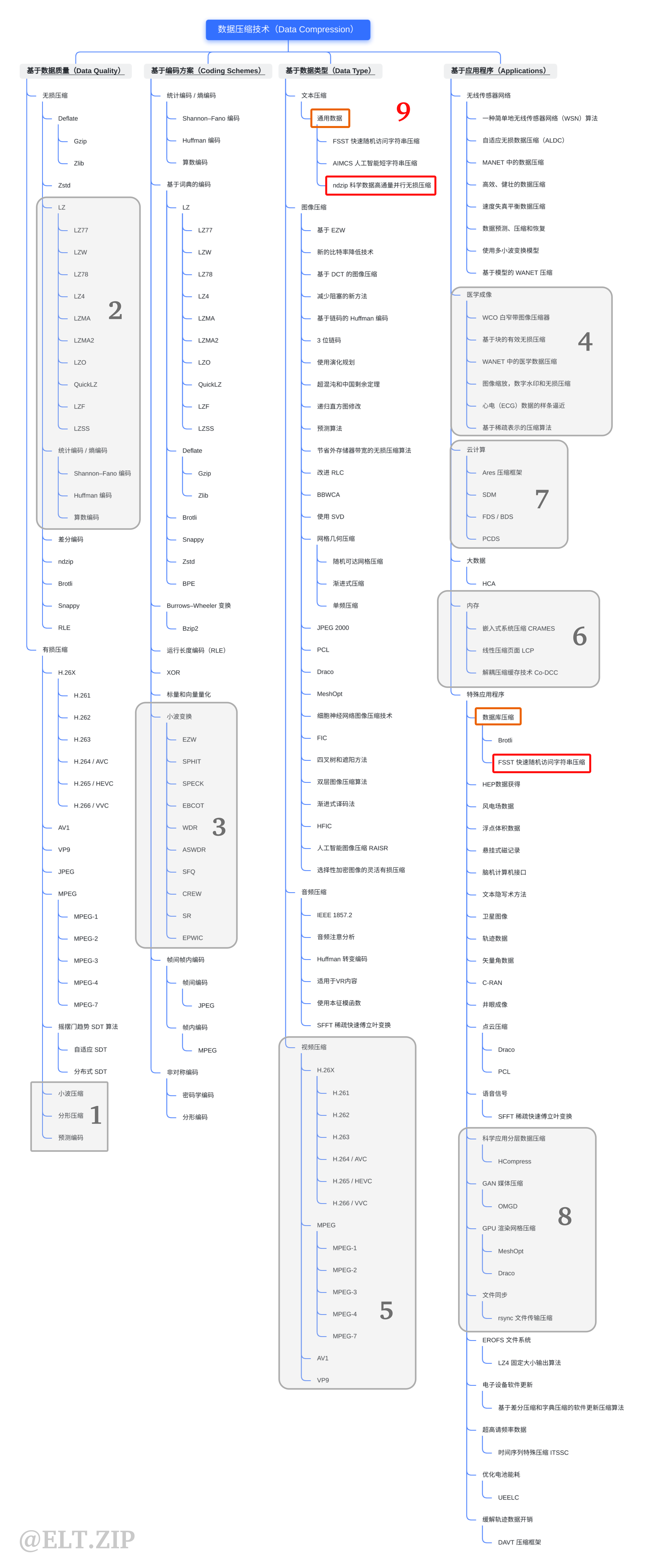
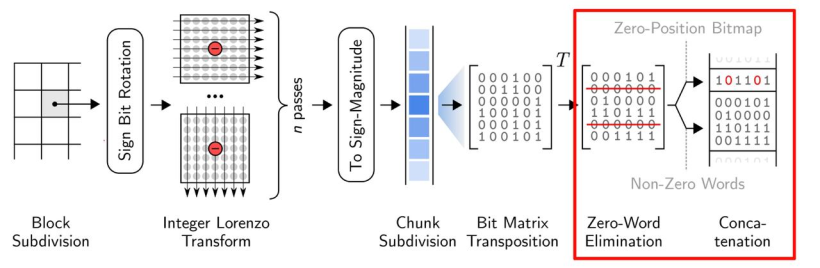
- ndzip 的算法主要分为块细分、整数洛伦兹变换以及残差编码三个部分。 大体流程:下图展示了ndzip压缩管道的所有步骤,首先它将输入的数据划分为固定大小的超立方体,并使用多维变换在块内对数据进行去相关,从而使其具有更短位表示残差。然后通过位矩阵变换消除公共零位来压缩剩余流。压缩后的数据块存储在报头旁边,报头显示了输出流中压缩数据块的位置。
- ndzip 不是一次性处理输入数据的整个 n 维网格,而是将其细分为独立压缩的小的超立方体,然后依次进行传输。 由于该算法需要多次传递数据,因此可以更好地使用处理器缓存,但会略微损失解相关的效率。块与块之间存在依赖,我们想要消除块之间的所有依赖关系,可以通过附加额外的数据来实现。 这里作者选择了4096个元素,则超立方体的大小可以表示为40961、642或163。对于单精度,这相当于16KB的内存;对于双精度,这相当于32KB的内存。预先确定块的大小能够在之后的步骤生成高度优化的机器码。 当网格范围不是块的大小的倍数时,边框元素将不被压缩地附加到输出中。
- 浮点洛伦兹预测器(Floating-point Lorenzo Predictor) 对于多维数据的预测是非常高效的,但是单独位模式的残差计算需要解码器从已经解码的临近值重建每个预测,从而引入限制并行计算的依赖。 因此,作者使用了整数洛伦兹变换( Integer Lorenzo Transform) 解决了这个问题。整数洛伦兹变换是一种直接计算整数域内的洛伦兹预测残差的近似的多道运算。下图便说明了这个过程。
- 关于残差编码,ndzip使用了与 MPC 相同的残差编码方案,使其可以在现在的CPU上高效的实现。大致流程如下: 残差使用了二进制补码进行表示,根据残差的符号,确定了补码第一位是1还是0。之后通过0消去对两者进行编码。 残差首先被转换成符号-数值(sign-magnitude)表示,只要残差为负,就对除了第一个比特外的所有比特进行翻转。 然后将残差流分成32个单精度或者64个双精度的值,对每个块进行 32x32(64x64) 的位矩阵变换 将来自相同位置的比特分组成单词,从输出中消去可以消去的0词 在每个块前面加上一个32位(64位)的头,将非0字的位置编码为位图。
-
- 运行 ndzip 需要以下环境,Catch2 可根据自己是否需要来选择是否安装。 CMake >= 3.15 Clang >= 10.0.0 Linux (我这里用的Ubuntu20) Boost >= 1.66 Catch2 >= 2.13.3 (可选,用于单元测试和微基准测试)
- CMake 在Ubuntu软件源中,安装非常简单,执行以下命令即可: sudo apt install cmake 版本检查(CMake >= 3.1.5): cmake --version 看到 CMake 版本大于3.1.5即可。
- Clang 也存在 Ubuntu软件源中,步骤和CMake差不多,命令如下: sudo apt install clang 版本检查(Clang >= 10.0.0): clang --version 可以看到 Clang 版本为10.0.0,符合要求
- Boostr 也存在 Ubuntu软件源中,命令如下: ```undefi`nedsudo apt-get install libboost-all-dev - 版本检查(Boost >= 1.66):```undefineddpkg -S /usr/include/boost/version.hpp
- Catch2需要去github上下载编译,命令如下: git clone https://github.com/catchorg/Catch2.gitcd Catch2cmake -Bbuild -H. -DBUILD_TESTING=OFFsudo cmake --build build/ --target install 等待编译添加完即可。
- 使用 CUDA + NVCC 构建 ndzip 使用 cuda,安装CUDA Toolkit: sudo apt-key del 7fa2af80 # 删除旧的GPG密钥,之前装过的要删掉wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pinsudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.debsudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.debsudo apt-get updatesudo apt-get -y install cuda 使用CUDA + NVCC 构建 ndzip(自己使用SYCL构建ndzip没跑出来。。。) cmake -B build -DCMAKE_CUDA_ARCHITECTURES=75 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_FLAGS="-march=native"cmake --build build -j 完成构建
- ndzip-gpu 通过变换在解耦多维数据时实现了高资源利用率。提出了一种用于垂直位打包的新颖、高效的曲速协同原语,提供了高吞吐量的数据缩减和扩展步骤, 为检查的数据提供了最佳的平均压缩比, 同时在双精度情况下的数据减少和吞吐量之间保持了有利的权衡。将数据集的压缩比定义为压缩大小除以未压缩大小(以字节为单位),比率越低表示压缩越强。在需要汇总比率的情况下,返回数据集上压缩比率的未加权算术平均值。
- SIMD(Single Instruction Multiple Data),单指令多数据流,能够复制多个操作数 ,并把它们打包在大型寄存器的一组指令集。 ndzip专为在支持 SIMD 的现代多核处理器上高效实施而量身定制,能够以接近主内存带宽的速度压缩和解压缩数据,显著优于现有方案。通过测量从系统内存压缩和解压缩到系统内存的时钟时间来评估性能。第三方实现允许在必要时进行内存操作。返回每秒未压缩字节的吞吐量,它转换为压缩输入和解压输出带宽。重复测量每个算法和数据集对,直到总运行时间超过一秒。在每次迭代之前,从 CPU 缓存中删除输入数据。 利用多维度的好处可以通过使用等效的一维变换来转换高维数据集来衡量。
- 通过设计一种考虑到目标架构特性的专用压缩算法,可以实现出色的资源使用以及压缩率和吞吐量之间极具竞争力的折中。基于我们新颖的小超立方体数据,利用了行整数洛伦佐变换(Integer Lorenzo Transform)和硬件友好的残差编码方案,ndzip 压缩器利用 SIMD 和线程并行性在消费类硬件上实现超过 10 GB/s 的压缩和解压缩速度,显著地减少数据量。 想了解更多关于开源的内容,请访问: 51CTO 开源基础软件社区 https://ost.51cto.com。

【本期看点】
- ndzip应用场景
- ndzip相关算法
- 残差编码复现
- SIMD
|
********** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
***************** |
|
场景 |
自动驾驶 / AR |
语音信号 |
流视频 |
GPU 渲染 |
科学、云计算 |
内存缩减 |
科学应用 |
医学图像 |
数据库服务器 |
人工智能图像 |
文本传输 |
GAN媒体压缩 |
图像压缩 |
文件同步 |
数据库系统 |
|
技术 |
点云压缩 |
稀疏快速傅里叶变换 |
有损视频压缩 |
网格压缩 |
动态选择压缩算法框架 |
无损压缩 |
分层数据压缩 |
医学图像压缩 |
无损通用压缩 |
人工智能图像压缩 |
短字符串压缩 |
GAN 压缩的在线多粒度蒸馏 |
图像压缩 |
文件传输压缩 |
快速随机访问字符串压缩 |
|
开源项目 |
SFFT |
Ares |
LZ4 |
DICOM |
Brotli |
RAISR |
AIMCS |
OMGD |
rsync |
FSST |
- 分布式计算以及高性能计算在机器学习、大数据学习与高级建模与模拟等新兴技术上都有使用。在航天航空、制造业、金融、医疗等多个领域也有着非常重要的作用。
- ndzip,是一种新的高吞吐量无损压缩算法,专门为浮点数据的n维网格而设计,为HPC互连带宽的的限制因素提供了一种有效的解决方案。
- 本文提出了一种新的压缩算法-ndzip,它基于一个快速,且并行整数近似的的知名预测器,并结合了对硬件友好的块细分方案;
- ndzip 的高性能多级并行实现,利用SIMD 和线程级并行;
- 对大量具有代表性的HPC 数据进行深入的性能评估,并与最新水平的专业浮点压缩器和通用压缩方案进行比较。
- FPZIP 使用洛伦兹预测器利用标量 n 维网格内点的直接邻域的平滑性,使用范围编码器压缩小的残值。该方案具有很高的压缩效率,特别是对于单精度值。
- FPC 使用一对基于哈希表的值预测器来压缩非结构化双精度数据流。它提供了一个可调参数,利用压缩效率提高速度。线程并行的pFPC 变体允许通过以块的形式处理输入数据来进一步确定压缩吞吐量的优先级。
- SPDP 结合了一维预测和LZ77变体,可以压缩单精度和双精度数据,而不需要对任何一种格式进行专门处理。
- MPC 是一种用于GPU 的快速压缩方案。将一个简单的一维值预测器与一个位重组方案相结合,可以很好地映射到目标硬件的残差中去零位。
- APE 和ACE 压缩器自适应地从多个值预测器中选择,将 n 维网格中的数据点与其已处理过的邻居解相关。残差使用一种变体的Golomb 编码进行压缩。
数值预测科学浮点数据中的单个数值通常在低阶尾数位表现出较高的熵,尾数也很少出现精确到重复,这降低了传统字典编码器的效率。相反,我们可以使用专门的方法对已经处理过的数据进行预测,只对残差进行编码。
- SPDP 和MPC 使用简单的固定步长值预测器,通过存储 k 个值,并用最近编码的第 k 个值预测每个点。
- FPC 和pFPC 使用一对基于哈希表的预测器来维护一个较大的内部状态,以利用值和值增量中的重复模式。
- fpzip 使用浮点洛伦兹预测器来估计 n 维空间中长度为 2 的超立方体的一个角的值。fpzip通过奇数条边可到达的所有其他角加起来,然后减去通过偶数条边可到达的角。当超立方体可用n - 1次隐式多项式表达时,预测精度是精确的。
- APE 和 ACE 扩展了fpzip预测器的思想,通过在每个维度上使用高维多项式,以更大的计算成本为代价提高了预测精度。
在无损压缩环境中,浮点减法不适合用来计算预测残差。小幅度的浮点值通常不会以简短的、可压缩的位的形式出现,而且浮点数的有限精度使浮点减法成为一种非双射的运算。因此,所有研究的算法都明确地计算位表示的残差。
- FPC和pFPC 使用逐位异或差,而SPDP和MPC 将操作数位重新解释为整数,并对整数减法的结果进行编码。
- APE和ACE 提供了两种变体。
- fpzip 也使用整数减法,但是它根据符号位对操作数进行反运算,以提高映射的连续性。
精确的预测会产生具有许多相同前导位的小幅度残差,即异或运算符为零以及二进制补码的整数减法的冗余符号位。对这些前导位进行有效编码是大多数研究方案中所采用的数据简化机制。
- fpzip 使用一个范围编码器来压缩前导冗余位的数量,紧接着复制剩余位。距离编码器能够产生的接近最佳的位串使得其非常节省空间。然而,所需的位粒度寻址难的问题难以有效解决。
- APE 和ACE 使用与fpzip类似的方法,但使用符号排序的Golomb 代码来编码冗余位的数量。
- FPC 和 pFPC 通过计算双精度残差中前导零字节的数量,使用固定映射对运行长度和4 bit中的预测部分进行编码。剩余部分将从第一个非零字节开始逐字输出。这种方法是无状态的,在不可压缩的情况下有可接受的1/16开销,代价是由于粒度较低而浪费比特。
- MPC 将剩余流分成 32 个单精度(或 64 个双精度)值的块,发出 32(64)个最高有效位,然后是 32(64)个第二最高有效位,依此类推。零字将从输出流中删除,并在每个编码所有非零字位置的块上替换为32或64位掩码。这种方法在不可压缩的情况下有非常低的开销,仅仅为1/32(1/64),由于字符粒度寻址,该方法在 GPU 上得到了有效的实现,但需要块内所有的残差具有相似的位宽才能实现。
- SPDP 从一个类似于 MPC 的重组策略开始,但是SPDP是在字节级别上的重组策略。SPDP接着使用字节粒度整数减差运算,并使用 lz77 系列编码器对结果流进行编码。这可以消除除前导零之外的重复模式,并使 SPDP 也能处理非浮点数据。
- ndzip 的算法主要分为块细分、整数洛伦兹变换以及残差编码三个部分。
- 大体流程:下图展示了ndzip压缩管道的所有步骤,首先它将输入的数据划分为固定大小的超立方体,并使用多维变换在块内对数据进行去相关,从而使其具有更短位表示残差。然后通过位矩阵变换消除公共零位来压缩剩余流。压缩后的数据块存储在报头旁边,报头显示了输出流中压缩数据块的位置。
- ndzip 不是一次性处理输入数据的整个 n 维网格,而是将其细分为独立压缩的小的超立方体,然后依次进行传输。
- 由于该算法需要多次传递数据,因此可以更好地使用处理器缓存,但会略微损失解相关的效率。块与块之间存在依赖,我们想要消除块之间的所有依赖关系,可以通过附加额外的数据来实现。
- 这里作者选择了4096个元素,则超立方体的大小可以表示为40961、642或163。对于单精度,这相当于16KB的内存;对于双精度,这相当于32KB的内存。预先确定块的大小能够在之后的步骤生成高度优化的机器码。
- 当网格范围不是块的大小的倍数时,边框元素将不被压缩地附加到输出中。
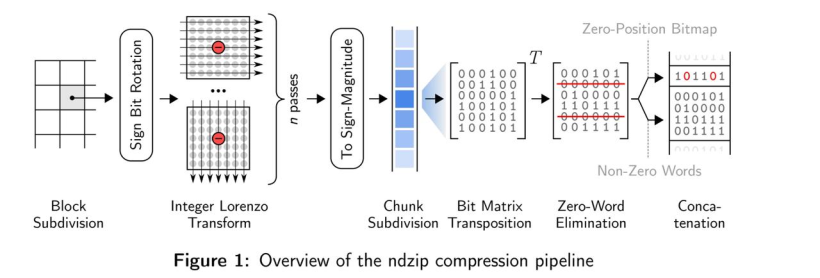
浮点洛伦兹预测器(Floating-point Lorenzo Predictor) 对于多维数据的预测是非常高效的,但是单独位模式的残差计算需要解码器从已经解码的临近值重建每个预测,从而引入限制并行计算的依赖。
因此,作者使用了整数洛伦兹变换( Integer Lorenzo Transform) 解决了这个问题。整数洛伦兹变换是一种直接计算整数域内的洛伦兹预测残差的近似的多道运算。下图便说明了这个过程。


- 关于残差编码,ndzip使用了与 MPC 相同的残差编码方案,使其可以在现在的CPU上高效的实现。大致流程如下:
残差使用了二进制补码进行表示,根据残差的符号,确定了补码第一位是1还是0。之后通过0消去对两者进行编码。
残差首先被转换成符号-数值(sign-magnitude)表示,只要残差为负,就对除了第一个比特外的所有比特进行翻转。
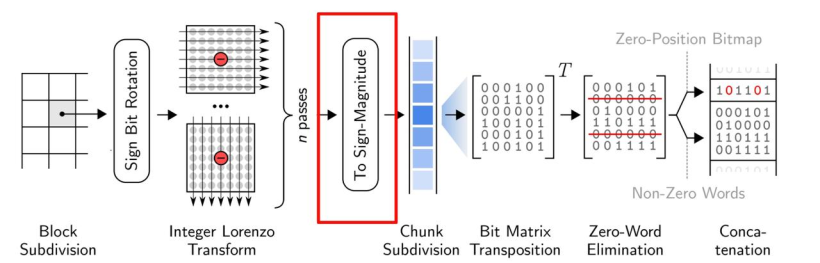
然后将残差流分成32个单精度或者64个双精度的值,对每个块进行 32x32(64x64) 的位矩阵变换
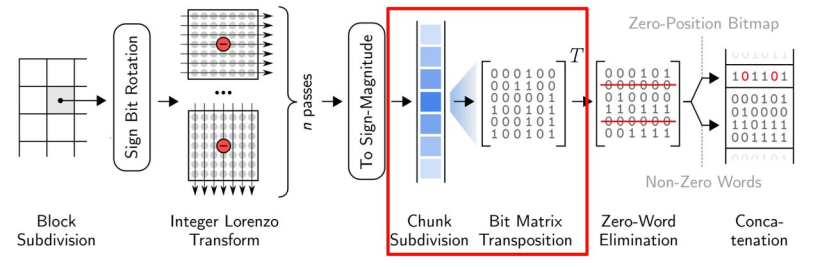
将来自相同位置的比特分组成单词,从输出中消去可以消去的0词
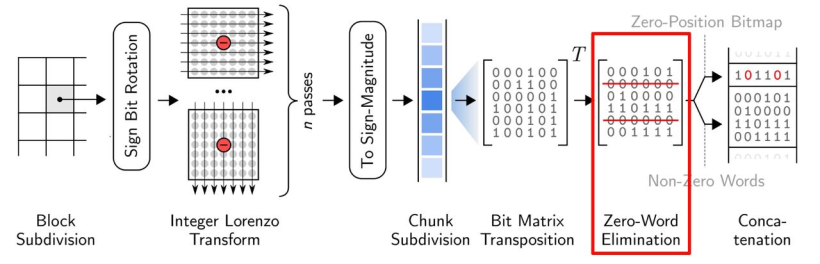
在每个块前面加上一个32位(64位)的头,将非0字的位置编码为位图。
- 上面的原理看的有点头秃,下面讲解如何快速上手ndzip。
- 点击进入 ndzip 的地址,git 下项目到本地。
运行 ndzip 需要以下环境,Catch2 可根据自己是否需要来选择是否安装。
- CMake >= 3.15
- Clang >= 10.0.0
- Linux (我这里用的Ubuntu20)
- Boost >= 1.66
- Catch2 >= 2.13.3 (可选,用于单元测试和微基准测试)
- CMake 在Ubuntu软件源中,安装非常简单,执行以下命令即可:
sudo apt install cmake
- 版本检查(CMake >= 3.1.5):
cmake --version
- 看到 CMake 版本大于3.1.5即可。

- Clang 也存在 Ubuntu软件源中,步骤和CMake差不多,命令如下:
sudo apt install clang
- 版本检查(Clang >= 10.0.0):
clang --version
- 可以看到 Clang 版本为10.0.0,符合要求

- Boostr 也存在 Ubuntu软件源中,命令如下:
```undefi`ned
sudo apt-get install libboost-all-dev
- 版本检查(Boost >= 1.66):
```undefined
dpkg -S /usr/include/boost/version.hpp
sudo apt-get install libboost-all-dev
```undefined
dpkg -S /usr/include/boost/version.hpp

- Catch2需要去github上下载编译,命令如下:
git clone https://github.com/catchorg/Catch2.git
cd Catch2
cmake -Bbuild -H. -DBUILD_TESTING=OFF
sudo cmake --build build/ --target install
- 等待编译添加完即可。
cd Catch2
cmake -Bbuild -H. -DBUILD_TESTING=OFF
sudo cmake --build build/ --target install
使用 CUDA + NVCC 构建 ndzip
- 使用 cuda,安装CUDA Toolkit:
sudo apt-key del 7fa2af80 # 删除旧的GPG密钥,之前装过的要删掉
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo apt-get update
sudo apt-get -y install cuda
- 使用CUDA + NVCC 构建 ndzip(自己使用SYCL构建ndzip没跑出来。。。)
cmake -B build -DCMAKE_CUDA_ARCHITECTURES=75 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_FLAGS="-march=native"
cmake --build build -j
- 完成构建

- 测试命令
- 测试ndzip压缩

- ndzip-gpu 通过变换在解耦多维数据时实现了高资源利用率。提出了一种用于垂直位打包的新颖、高效的曲速协同原语,提供了高吞吐量的数据缩减和扩展步骤, 为检查的数据提供了最佳的平均压缩比, 同时在双精度情况下的数据减少和吞吐量之间保持了有利的权衡。将数据集的压缩比定义为压缩大小除以未压缩大小(以字节为单位),比率越低表示压缩越强。在需要汇总比率的情况下,返回数据集上压缩比率的未加权算术平均值。
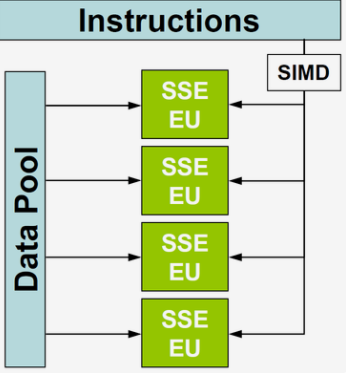
- SIMD(Single Instruction Multiple Data),单指令多数据流,能够复制多个操作数 ,并把它们打包在大型寄存器的一组指令集。
- ndzip专为在支持 SIMD 的现代多核处理器上高效实施而量身定制,能够以接近主内存带宽的速度压缩和解压缩数据,显著优于现有方案。通过测量从系统内存压缩和解压缩到系统内存的时钟时间来评估性能。第三方实现允许在必要时进行内存操作。返回每秒未压缩字节的吞吐量,它转换为压缩输入和解压输出带宽。重复测量每个算法和数据集对,直到总运行时间超过一秒。在每次迭代之前,从 CPU 缓存中删除输入数据。
利用多维度的好处可以通过使用等效的一维变换来转换高维数据集来衡量。
- 为了估计新型整数洛伦佐变换(ILT)的有效性,我们用其他预测方法代替了实现中的变换步骤,并比较了得到的压缩比,通过使用等效的一维变换来转换高维数据集来衡量。
- 如图显示了具有相同维度的所有数据集的平均压缩比,相对于在各自维度中观察到的最差压缩比进行了缩放。
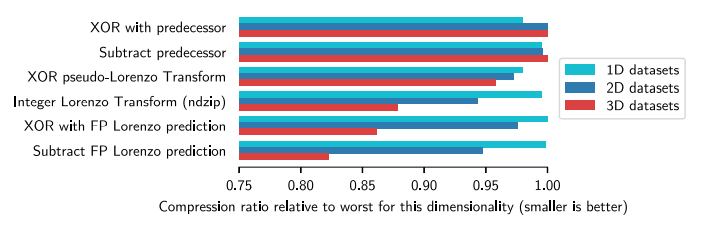
- 因为该维度相对最差的压缩比(越小越好),对于一维数据集,所有方案大致相同。总体上看,FLP最好,最差的选择是两个一维预测器,这表明基于洛伦佐的组件显著受益于更高的维度,选择余数运算对于逼近 FLP 的相关特征至关重要。
算术平均未压缩吞吐量 - 在测试数据上比较通过检查的压缩器实现,实现的吞吐量和压缩比。 根据设计,同时并非所有算法都能同时处理单精度值和双精度值。有些算法有一个或多个可调参数体现为连续的线,而ndzip,没有可调的行为。
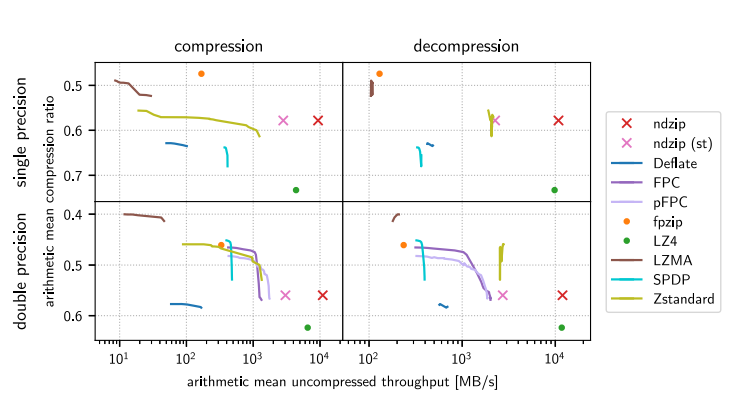
- 通用算法可以在浮点数据上实现高压缩比,但只能以牺牲大量计算资源为代价。比如,LZMA 在双精度值上实现了最高的压缩比,与最强的单精度压缩器 fpzip 不相上下,同时花费更多压缩我们最大的数据集。LZ4 实现了比任何其他审查过的单线程算法更高的压缩和解压缩吞吐量,同时还提供了最差的数据缩减。Zstandard 提供了一个非常好的权衡,在单精度数据上主导 Deflate 和专门的 SPDP。大多数专业算法能够在至少一个维度上胜过通用方案。而Fpzip 是最强大的单精度压缩器,而且仅以中等吞吐量为代价,但在解压缩方面失去了吞吐量比较.
- 所以ndzip 是最快的专用压缩器和解压缩器,具有显着优势(“st”)。 对于双精度数据集,稍差一些。与一些速度较慢的算法相比,我们的压缩器提供了更低的压缩比,但在吞吐量方面明显优于它唯一的竞争对手 LZ4。
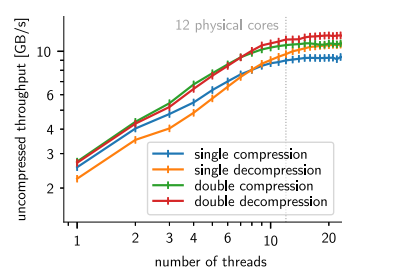
- 通过设计一种考虑到目标架构特性的专用压缩算法,可以实现出色的资源使用以及压缩率和吞吐量之间极具竞争力的折中。基于我们新颖的小超立方体数据,利用了行整数洛伦佐变换(Integer Lorenzo Transform)和硬件友好的残差编码方案,ndzip 压缩器利用 SIMD 和线程并行性在消费类硬件上实现超过 10 GB/s 的压缩和解压缩速度,显著地减少数据量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。





