
文章目录
- 在接触一些大型项目构建速度慢的很离谱,有些项目在 编译构建上30分钟超时,有些构建到一半内存溢出。但当时一些通用的 Webpack 构建优化方案要么已经接入,要么场景不适用: 已接入的方案效果有限。比如 cache-loader、thread-loader,能优化编译阶段的速度,但对于依赖解析、代码压缩、SourceMap 生成等环节无能为力 作为前端基建方案,业务依赖差异极大,难以针对特定依赖优化,如 DllPlugin 方案 作为移动端打包方案,追求极致的首屏加载速度,难以接受频繁的异步资源请求,如 Module Federation、Common Chunk 方案 存在一码多产物场景,需要单仓库多模式构建(1.0/2.0 * 主包/分包)下缓存复用,难以接受耦合度高的缓存方案,如 Persistent Caching 在这种情况下,只好另辟蹊径去寻找更多优化方案,这篇文章主要就是介绍这些“非主流”的优化方案,以及引发的思考。 今天带来的是webapck4sourceMap阶段。
- SourceMap生成流程 SourceMap 生成过程中,由于项目过大导致需要计算处理的映射节点(SourceNode)特别多(遇到过10^6数量级的项目),这也导致 SourceMap 生成过程中内存飙升频繁 GC,构建十分缓慢甚至 OOM。 Webpack 内部有大量的代码拼接工作,而每一次代码拼接都涉及到 SourceMap 的处理,因此 Webpack 内封装了 webpack-sources,其中 SourceMapSource 用于保存 SourceMap,ConcatSource 用于代码拼接, SourceMap 操作使用 source-map 和 source-list-map 库来处理。 而其内部实际上是在运行 sourceAndMap()/map() 方法时才进行计算: // webpack-sources/SourceMapSource class SourceMapSource extends Source { // ... node(options) { // 此处进行真正的计算 var sourceMap = this._sourceMap; var node = SourceNode.fromStringWithSourceMap(this._value, new SourceMapConsumer(sourceMap)); node.setSourceContent(this._name, this._originalSource); var innerSourceMap = this._innerSourceMap; if(innerSourceMap) { node = applySourceMap(node, new SourceMapConsumer(innerSourceMap), this._name, this._removeOriginalSource); } return node; } // ... } // webpack-sources/SourceAndMapMixin proto.sourceAndMap = function (options) { options = options || {}; if (options.columns === false) { return this.listMap(options).toStringWithSourceMap({ file: "x", }); } var res = this.node(options).toStringWithSourceMap({ file: "x", }); return { source: res.code, map: res.map.toJSON(), }; };
- 很显然,如果把所有模块的 SourceMap 都放到最后一起来计算,对主进程长时间占用导致 SourceMap 生成缓慢。可以通过如下方法进行优化:
使用行映射 SourceMap
SourceMap 并行化
SourceNode 内存优化
- SourceMap 的本质就是大量的 SourceNode 组成,每一个 SourceNode 存储了产物的位置到源码位置的映射关系。通常映射关系是行号+列号,但我们排查bug时候一般只看哪一行,具体哪一列看的不多。如果忽略列号则可以大幅度减少 SourceNode 的数量。 SourceMapDevToolPlugin 中的 columns 设为 true 时就是行映射 SourceMap。但这个插件处理的逻辑已经是在最后产物生成阶段,而在整个 Webpack 构建流程中流转的 SourceMap 依然是行列映射。因此可以直接代理掉 SourceMapSource 的 map 方法,写死 columns 为 true。
- SourceMap 最后一起堆积在主进程中生成是非常缓慢的,因此可以考虑在模块级压缩的时候,手动模拟 node() 方法,触发一下 applySourceMap 方法提前生成 SourceNode,并将 SourceNode 序列化传递回主进程,当主进程需要使用时直接获取即可。
- 当字符串被 split 时,行为与 substr 不太一样,split 会生成字符串的拷贝,占用额外的内存(chrome memory profile 中为string),而 substr 会生成引用,字符串不会拷贝占用额外内存(chrome memory profile 中为 sliced string),但与此同时也意味着父字符串无法被 GC 回收。 const bigstring = '00000\n'.repeat(50000); console.log(bigstring); // 触发生成 const array = bigstring.split('\n'); const bigstring = '00000\n'.repeat(500000); console.log(bigstring) const array = []; for (let i = 0; i < 100000;i++) { array.push(bigstring.substr(i*5,i*5+5)); } 而看 source-map 中 SourceNode 的代码可以发现: SourceNode 会将完整代码根据换行符 split 切分(生成大量 string 内存占用)。 根据 mapping 对代码求子串并保存(此时意味着这些 string 无法被释放)。 // source-map/SourceNode SourceNode.fromStringWithSourceMap = function SourceNode_fromStringWithSourceMap( aGeneratedCode, aSourceMapConsumer, aRelativePath ) { // ... // 此处进行了代码切分 var remainingLines = aGeneratedCode.split(REGEX_NEWLINE); // ... aSourceMapConsumer.eachMapping(function (mapping) { if (lastMapping !== null) { if (lastGeneratedLine < mapping.generatedLine) { // ... } else { var nextLine = remainingLines[remainingLinesIndex] || ''; // 此处获取子串并长久保存 var code = nextLine.substr(0, mapping.generatedColumn - lastGeneratedColumn); // ... addMappingWithCode(lastMapping, code); // No more remaining code, continue lastMapping = mapping; return; } } //... }, this); // ... }; 那么这个昂贵的 "code" 字段干什么用的呢?实际上只有如下两个功能: 每一个 code 都会生成一个子 SourceNode,而最终递归生成的子 SourceNode 在 walk 阶段又会拼接回产物代码。 如果包含了换行符,则会用来做映射位置的偏移计算。 // source-map/SourceNode SourceNode.prototype.toStringWithSourceMap = function SourceNode_toStringWithSourceMap(aArgs) { // ... this.walk(function (chunk, original) { generated.code += chunk; //... for (var idx = 0, length = chunk.length; idx < length; idx++) { if (chunk.charCodeAt(idx) === NEWLINE_CODE) { generated.line++; generated.column = 0; // Mappings end at eol // ... } else { generated.column++; } } }); this.walkSourceContents(function (sourceFile, sourceContent) { map.setSourceContent(sourceFile, sourceContent); }); return { code: generated.code, map: map }; }; 那么问题来了,产物代码有很多其他渠道能够获取不需要在这里计算。而仅仅为了换行计算浪费如此大量的内存显然是不合理的。因此可以在一开始就把换行符的位置计算出来,保留在 SourceNode 内部,然后让切分出来的字符被 GC 回收,等到 walk 的时候直接拿这些换行符记录进行计算即可。
-
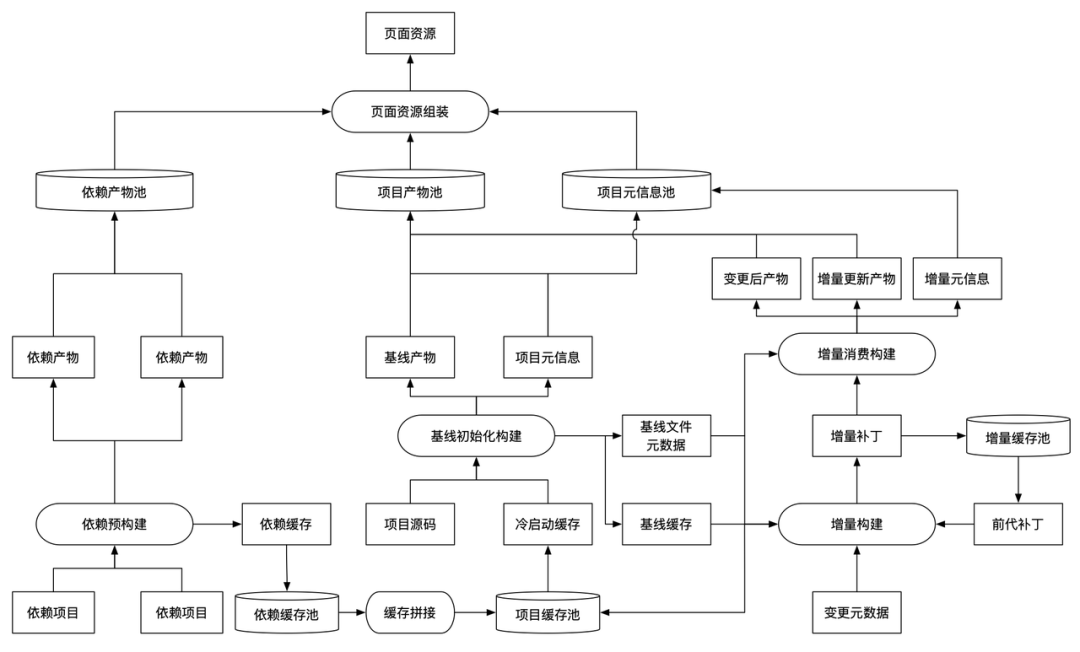
- 前面构建生成了缓存,我们希望缓存是可移植、可拼接、预生成的: 可移植:中间产物不依赖特定环境,放到其他场景下依然能够使用。 可拼接:对于每一个项目都有自己的中间产物,而当一个聚合的项目使用这些项目时,也可以通过聚合生成自己的中间产物。 预生成:中间产物可以提前生成,存放到云端,在任何有需要的场景下载使用。 通过预生成,按需下发,动态拼接的方式,就能真正做到“绝不构建第二次”。
- 缓存与环境解耦是可以让缓存跨机器使用,遗憾的是 Webpack 在其模块的 request 中包含绝对路径(要找到对应的文件),导致与其相关的 AST 解析、模块 ID 生成等等都受到影响。因此要做到可移植缓存,需要如下改造: 统一的缓存管理:不受控的缓存难以做后续的环境解耦。 路径替换&复原:对于写入缓存的所有内容,一旦出现了本地路径,都需要替换成占位符。读取时则需要将占位符恢复成新环境的路径。 AST 偏移矫正:由于路径替换过程中,路径长度发生变化,从而导致上述依赖解析阶段的 AST 位置信息缓存失效,因此需要根据路径长度差异对 AST 位置进行矫正。 Hash 代理:由于构建流程中有大量的 Hash 生成场景,而一旦包含了本地路径字符串加入到 Hash 生成中,则必然导致 Hash 在新环境下无法被匹配。
- 有了可移植的缓存,就能实现增量的构建。核心思路如下: 项目某个特定版本源码作为项目基线,基线初始化构建生成基线缓存和基线文件元数据 当文件发生变化时: 收集变化的文件生成变更元数据。 变更元数据 + 基线缓存 + 基线文件元数据,构建生成变更后产物+热更新产物,同时产出增量补丁。 增量补丁主要包含文件目录的增量、缓存的增量。 如果有前代增量补丁,可以合并。 当环境发生变化时,在新环境下: 增量补丁+基线缓存+基线文件元数据,通过增量消费构建,也可以再次产出构建产物。 当需要提升一个特定增量补丁的版本作为基线时,将其增量变更与基线缓存、基线文件元数据合并即可。 增量构建最大的好处:解决长迭代链导致的缓存存储成本爆炸问题。 举个例子:如果要做一个类似于 codepen、jsfiddle 那样的 playground,可以在线编辑项目代码,迭代中的每次编辑都可以回退,同时也能随时将一次修改派生成为一个新的迭代。 在这种场景下,显然不能给每次代码修改都完整复刻一套缓存。增量的构建仅需要保存一个基线和对应版本相对于基线的增量,当切换到一个特定版本时,使用基线+增量就可以编译出最新的产物,实现版本的快速恢复。这个同理可以应用在项目自身迭代过程的构建缓存池中。
- 一些思考 函数编写:牢记“引用透明”原则,这是缓存、并行化的基本前提。 模型设计:保证可序列化/反序列化,为缓存、并行化打好基础。 缓存设计:所有缓存应当结构简单且路径无关,保证缓存可移植、可拼接。 对象引用:尽早释放巨大对象的引用,仅保留需要的数据。 插件机制:tapable 这种 pub/sub 机制是否真的合理且灵活,也许高阶函数更加合适。 TypeScript:非 TS 代码阅读难度很大,运行时的数据流不去 debug 无法理解。 一些脑洞:

Hello,大家好,我是松宝写代码,写宝写的不止是代码。
由于优化都是在 Webpack 4 上做的,当时 Webpack 5 还未稳定,现在使用 Webpack 5 时可能有些优化方案不再需要或方案不一致,这里主要分享思路,可供参考。
在接触一些大型项目构建速度慢的很离谱,有些项目在 编译构建上30分钟超时,有些构建到一半内存溢出。但当时一些通用的 Webpack 构建优化方案要么已经接入,要么场景不适用:
- 已接入的方案效果有限。比如 cache-loader、thread-loader,能优化编译阶段的速度,但对于依赖解析、代码压缩、SourceMap 生成等环节无能为力
- 作为前端基建方案,业务依赖差异极大,难以针对特定依赖优化,如 DllPlugin 方案
- 作为移动端打包方案,追求极致的首屏加载速度,难以接受频繁的异步资源请求,如 Module Federation、Common Chunk 方案
- 存在一码多产物场景,需要单仓库多模式构建(1.0/2.0 * 主包/分包)下缓存复用,难以接受耦合度高的缓存方案,如 Persistent Caching
在这种情况下,只好另辟蹊径去寻找更多优化方案,这篇文章主要就是介绍这些“非主流”的优化方案,以及引发的思考。
今天带来的是webapck4sourceMap阶段。
SourceMap生成流程 SourceMap 生成过程中,由于项目过大导致需要计算处理的映射节点(SourceNode)特别多(遇到过10^6数量级的项目),这也导致 SourceMap 生成过程中内存飙升频繁 GC,构建十分缓慢甚至 OOM。
Webpack 内部有大量的代码拼接工作,而每一次代码拼接都涉及到 SourceMap 的处理,因此 Webpack 内封装了 webpack-sources,其中 SourceMapSource 用于保存 SourceMap,ConcatSource 用于代码拼接, SourceMap 操作使用 source-map 和 source-list-map 库来处理。
而其内部实际上是在运行 sourceAndMap()/map() 方法时才进行计算:
// webpack-sources/SourceMapSource
class SourceMapSource extends Source {
// ...
node(options) {
// 此处进行真正的计算
var sourceMap = this._sourceMap;
var node = SourceNode.fromStringWithSourceMap(this._value, new SourceMapConsumer(sourceMap));
node.setSourceContent(this._name, this._originalSource);
var innerSourceMap = this._innerSourceMap;
if(innerSourceMap) {
node = applySourceMap(node, new SourceMapConsumer(innerSourceMap), this._name, this._removeOriginalSource);
}
return node;
}
// ...
}
// webpack-sources/SourceAndMapMixin
proto.sourceAndMap = function (options) {
options = options || {};
if (options.columns === false) {
return this.listMap(options).toStringWithSourceMap({
file: "x",
});
}
var res = this.node(options).toStringWithSourceMap({
file: "x",
});
return {
source: res.code,
map: res.map.toJSON(),
};
};很显然,如果把所有模块的 SourceMap 都放到最后一起来计算,对主进程长时间占用导致 SourceMap 生成缓慢。可以通过如下方法进行优化:
- 使用行映射 SourceMap
- SourceMap 并行化
- SourceNode 内存优化
SourceMap 的本质就是大量的 SourceNode 组成,每一个 SourceNode 存储了产物的位置到源码位置的映射关系。通常映射关系是行号+列号,但我们排查bug时候一般只看哪一行,具体哪一列看的不多。如果忽略列号则可以大幅度减少 SourceNode 的数量。
SourceMapDevToolPlugin 中的 columns 设为 true 时就是行映射 SourceMap。但这个插件处理的逻辑已经是在最后产物生成阶段,而在整个 Webpack 构建流程中流转的 SourceMap 依然是行列映射。因此可以直接代理掉 SourceMapSource 的 map 方法,写死 columns 为 true。
SourceMap 最后一起堆积在主进程中生成是非常缓慢的,因此可以考虑在模块级压缩的时候,手动模拟 node() 方法,触发一下 applySourceMap 方法提前生成 SourceNode,并将 SourceNode 序列化传递回主进程,当主进程需要使用时直接获取即可。
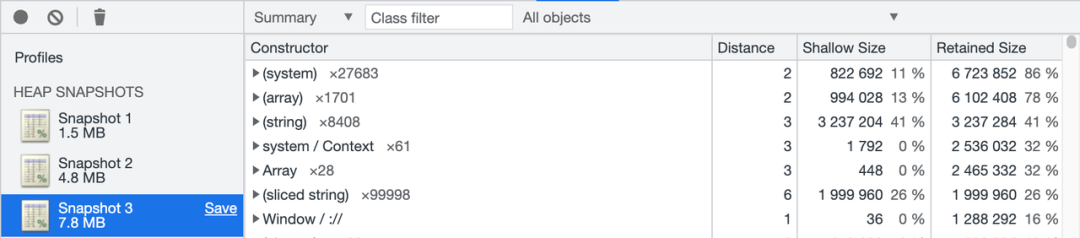
当字符串被 split 时,行为与 substr 不太一样,split 会生成字符串的拷贝,占用额外的内存(chrome memory profile 中为string),而 substr 会生成引用,字符串不会拷贝占用额外内存(chrome memory profile 中为 sliced string),但与此同时也意味着父字符串无法被 GC 回收。
const bigstring = '00000\n'.repeat(50000);
console.log(bigstring); // 触发生成
const array = bigstring.split('\n');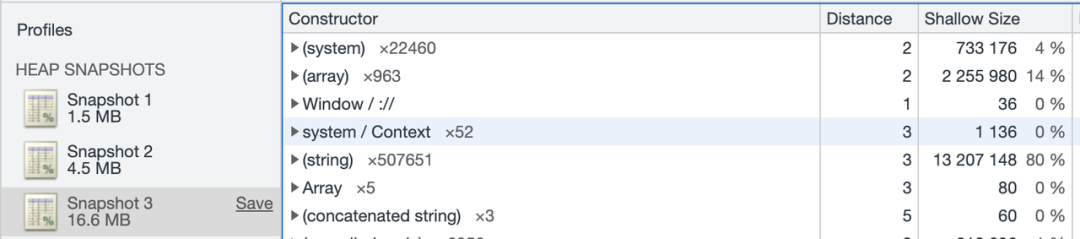
const bigstring = '00000\n'.repeat(500000);
console.log(bigstring)
const array = [];
for (let i = 0; i < 100000;i++) {
array.push(bigstring.substr(i*5,i*5+5));
}
而看 source-map 中 SourceNode 的代码可以发现:
- SourceNode 会将完整代码根据换行符 split 切分(生成大量 string 内存占用)。
- 根据 mapping 对代码求子串并保存(此时意味着这些 string 无法被释放)。
// source-map/SourceNode
SourceNode.fromStringWithSourceMap = function SourceNode_fromStringWithSourceMap(
aGeneratedCode,
aSourceMapConsumer,
aRelativePath
) {
// ...
// 此处进行了代码切分
var remainingLines = aGeneratedCode.split(REGEX_NEWLINE);
// ...
aSourceMapConsumer.eachMapping(function (mapping) {
if (lastMapping !== null) {
if (lastGeneratedLine < mapping.generatedLine) {
// ...
} else {
var nextLine = remainingLines[remainingLinesIndex] || '';
// 此处获取子串并长久保存
var code = nextLine.substr(0, mapping.generatedColumn - lastGeneratedColumn);
// ...
addMappingWithCode(lastMapping, code);
// No more remaining code, continue
lastMapping = mapping;
return;
}
}
//...
}, this);
// ...
};那么这个昂贵的 "code" 字段干什么用的呢?实际上只有如下两个功能:
- 每一个 code 都会生成一个子 SourceNode,而最终递归生成的子 SourceNode 在 walk 阶段又会拼接回产物代码。
- 如果包含了换行符,则会用来做映射位置的偏移计算。
// source-map/SourceNode
SourceNode.prototype.toStringWithSourceMap = function SourceNode_toStringWithSourceMap(aArgs) {
// ...
this.walk(function (chunk, original) {
generated.code += chunk;
//...
for (var idx = 0, length = chunk.length; idx < length; idx++) {
if (chunk.charCodeAt(idx) === NEWLINE_CODE) {
generated.line++;
generated.column = 0;
// Mappings end at eol
// ...
} else {
generated.column++;
}
}
});
this.walkSourceContents(function (sourceFile, sourceContent) {
map.setSourceContent(sourceFile, sourceContent);
});
return { code: generated.code, map: map };
};那么问题来了,产物代码有很多其他渠道能够获取不需要在这里计算。而仅仅为了换行计算浪费如此大量的内存显然是不合理的。因此可以在一开始就把换行符的位置计算出来,保留在 SourceNode 内部,然后让切分出来的字符被 GC 回收,等到 walk 的时候直接拿这些换行符记录进行计算即可。
前面构建生成了缓存,我们希望缓存是可移植、可拼接、预生成的:
- 可移植:中间产物不依赖特定环境,放到其他场景下依然能够使用。
- 可拼接:对于每一个项目都有自己的中间产物,而当一个聚合的项目使用这些项目时,也可以通过聚合生成自己的中间产物。
- 预生成:中间产物可以提前生成,存放到云端,在任何有需要的场景下载使用。
通过预生成,按需下发,动态拼接的方式,就能真正做到“绝不构建第二次”。
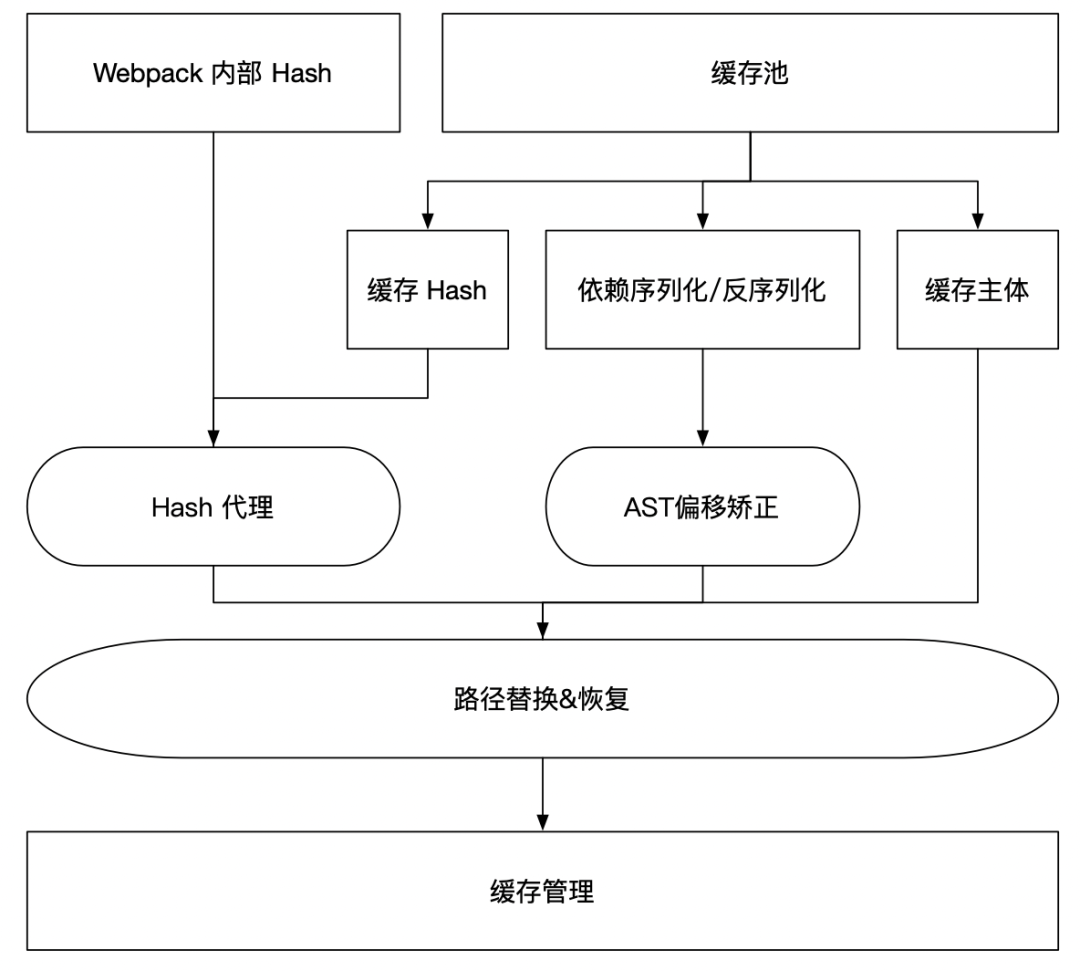
缓存与环境解耦是可以让缓存跨机器使用,遗憾的是 Webpack 在其模块的 request 中包含绝对路径(要找到对应的文件),导致与其相关的 AST 解析、模块 ID 生成等等都受到影响。因此要做到可移植缓存,需要如下改造:
- 统一的缓存管理:不受控的缓存难以做后续的环境解耦。
- 路径替换&复原:对于写入缓存的所有内容,一旦出现了本地路径,都需要替换成占位符。读取时则需要将占位符恢复成新环境的路径。
- AST 偏移矫正:由于路径替换过程中,路径长度发生变化,从而导致上述依赖解析阶段的 AST 位置信息缓存失效,因此需要根据路径长度差异对 AST 位置进行矫正。
- Hash 代理:由于构建流程中有大量的 Hash 生成场景,而一旦包含了本地路径字符串加入到 Hash 生成中,则必然导致 Hash 在新环境下无法被匹配。
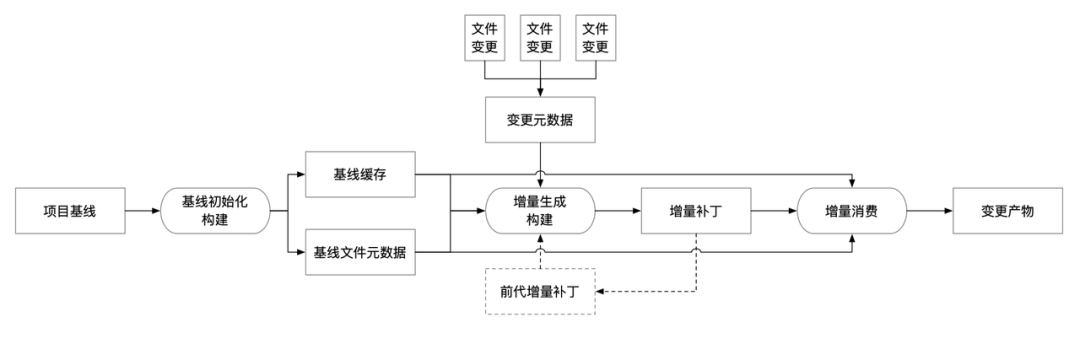
有了可移植的缓存,就能实现增量的构建。核心思路如下:
- 项目某个特定版本源码作为项目基线,基线初始化构建生成基线缓存和基线文件元数据
- 当文件发生变化时:
- 收集变化的文件生成变更元数据。
- 变更元数据 + 基线缓存 + 基线文件元数据,构建生成变更后产物+热更新产物,同时产出增量补丁。
- 增量补丁主要包含文件目录的增量、缓存的增量。
- 如果有前代增量补丁,可以合并。
- 当环境发生变化时,在新环境下:
- 增量补丁+基线缓存+基线文件元数据,通过增量消费构建,也可以再次产出构建产物。
- 当需要提升一个特定增量补丁的版本作为基线时,将其增量变更与基线缓存、基线文件元数据合并即可。
增量构建最大的好处:解决长迭代链导致的缓存存储成本爆炸问题。
举个例子:如果要做一个类似于 codepen、jsfiddle 那样的 playground,可以在线编辑项目代码,迭代中的每次编辑都可以回退,同时也能随时将一次修改派生成为一个新的迭代。
在这种场景下,显然不能给每次代码修改都完整复刻一套缓存。增量的构建仅需要保存一个基线和对应版本相对于基线的增量,当切换到一个特定版本时,使用基线+增量就可以编译出最新的产物,实现版本的快速恢复。这个同理可以应用在项目自身迭代过程的构建缓存池中。
一些思考
- 函数编写:牢记“引用透明”原则,这是缓存、并行化的基本前提。
- 模型设计:保证可序列化/反序列化,为缓存、并行化打好基础。
- 缓存设计:所有缓存应当结构简单且路径无关,保证缓存可移植、可拼接。
- 对象引用:尽早释放巨大对象的引用,仅保留需要的数据。
- 插件机制:tapable 这种 pub/sub 机制是否真的合理且灵活,也许高阶函数更加合适。
- TypeScript:非 TS 代码阅读难度很大,运行时的数据流不去 debug 无法理解。
一些脑洞:
© 版权声明
文章版权归作者所有,未经允许请勿转载。








