
文章目录
- 作为Transformer架构奠基架构合著者之一,Llion Jones向彭博确认,将于本月晚些时候离开谷歌日本,并计划在休假后创办一家公司。 图片 Jones在给彭博社的一封消息中写道: 离开谷歌并不是一个容易的决定,我与他们度过了非常精彩的十年,但是现在是尝试一些不同的事情的时候了。鉴于人工智能领域的势头和进展,现在是构建新事物的好时机。 谷歌的一位发言人没有立即回应置评请求。 根据个人领英主页,Llion Jones于2015年6月加入了谷歌,至今已经任职8年。此前他曾就职于YouTube、Delcam。 图片 他曾在伯明翰大学取得了和计算机专业的学士和硕士学位。 到目前为止,Jones的谷歌学术主页中, 引用最高的一篇文章当属17年横空出世的「Attention Is All You Need」,引用数81266。 图片 Transformer现在是大型语言模型的关键组成部分,而这种技术是OpenAI的ChatGPT等流行人工智能产品的基础。 在过去的几年中,该论文的作者们已经创办了一些知名的初创企业,包括为企业客户提供LLM的Cohere,以及允许用户创建模仿名人和历史人物的聊天机器人的Character.AI。 随着Jones的离开,意味着所有八位作者都已经离开了谷歌。
- 那么,其他七子现又身处何处呢? Jakob Uszkoreit被公认是Transformer架构的主要贡献者。 他在2021年中离开了谷歌,并共同创立了Inceptive Labs,致力于使用神经网络设计mRNA。 到目前为止,他们已经筹集了2000万美元,并且团队规模也超过了20人。 图片 Ashish Vaswani在2021年底离开谷歌,创立了AdeptAILabs。 可以说,AdeptAILabs正处在高速发展的阶段。 目前,公司不仅已经筹集了4.15亿美元,而且也估值超过了10亿美元。 此外,团队规模也刚刚超过了40人。 然而,Ashish却在几个月前离开了Adept。 在Transformers论文中,Niki Parmar是唯一的女性作者。 她在2021年底离开谷歌,并和刚刚提到的Ashish Vaswani一起,创立了AdeptAILabs。 不过,Niki在几个月前也离开了Adept。 Noam Shazeer在Google工作了20年后,于2021年底离开了Google。 随后,他便立刻与自己的朋友Dan Abitbol一起,创立了Character AI。 虽然公司只有大约20名员工,但效率却相当之高。 目前,他们已经筹集了近2亿美元,并即将跻身独角兽的行列。 Aidan Gomez在2019年9月离开了Google Brain,创立了CohereAI。 经过3年的稳定发展后,公司依然正在扩大规模——Cohere的员工数量最近超过了180名。 与此同时,公司筹集到的资金也即将突破4亿美元大关。 Lukasz Kaiser是TensorFlow的共同作者人之一,他在2021年中离开了谷歌,加入了OpenAI。 Illia Polosukhin在2017年2月离开了谷歌,于2017年6月创立了NEAR Protocol。 目前,NEAR估值约为20亿美元。 与此同时,公司已经筹集了约3.75亿美元,并进行了大量的二次融资。
- Transformer诞生之前,AI圈的人在自然语言处理中大都采用基于RNN(循环神经网络)的编码器-解码器(Encoder-Decoder)结构来完成序列翻译。 然而,RNN及其衍生的网络最致命的缺点就是慢。关键问题就在于前后隐藏状态的依赖性,无法实现并行。 Transformer的现世可谓是如日中天,让许多研究人员开启了追星之旅。 2017年,8位谷歌研究人员发表了Attention is All You Need。可以说,这篇论文是NLP领域的颠覆者。 论文地址:https://arxiv.org/pdf/1706.03762.pdf 它完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,进而实现了并行计算。 甚至,有人发问「有了Transformer框架后是不是RNN完全可以废弃了?」 图片 JimFan所称Transformer当初的设计是为了解决翻译问题,毋庸置疑。 谷歌当年发的博客,便阐述了Transformer是一种语言理解的新型神经网络架构。 图片 https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html 具体来讲,Transformer由四部分组成:输入、编码器、解码器,以及输出。 输入字符首先通过Embedding转为向量,并加入位置编码(Positional Encoding)来添加位置信息。 然后,通过使用多头自注意力和前馈神经网络的「编码器」和「解码器」来提取特征,最后输出结果。 如下图所示,谷歌给出了Transformer如何用在机器翻译中的例子。 机器翻译的神经网络通常包含一个编码器,在读取完句子后生成一个表征。空心圆代表着Transformer为每个单词生成的初始表征。 然后,利用自注意力,从所有其他的词中聚合信息,在整个上下文中为每个词产生一个新表征,由实心圆表示。 接着,将这个步骤对所有单词并行重复多次,依次生成新的表征。 图片 同样,解码器的过程与之类似,但每次从左到右生成一个词。它不仅关注其他先前生成的单词,还关注编码器生成的最终表征。 2019年,谷歌还专门为其申请了专利。 图片 自此,在自然语言处理中,Transformer逆袭之路颇有王者之风。 归宗溯源,现在各类层出不穷的GPT(Generative Pre-trained Transformer),都起源于这篇17年的论文。 然而,Transformer燃爆的不仅是NLP学术圈。
- 2017年的谷歌博客中,研究人员曾对Transformer未来应用潜力进行了畅享: 不仅涉及自然语言,还涉及非常不同的输入和输出,如图像和视频。 图片 没错,在NLP领域掀起巨浪后,Transformer又来「踢馆」计算机视觉领域。甚至,当时许多人狂呼Transformer又攻下一城。 自2012年以来,CNN已经成为视觉任务的首选架构。 随着越来越高效的结构出现,使用Transformer来完成CV任务成为了一个新的研究方向,能够降低结构的复杂性,探索可扩展性和训练效率。 2020年10月,谷歌提出的Vision Transformer (ViT),不用卷积神经网络(CNN),可以直接用Transformer对图像进行分类。 图片 值得一提的是,ViT性能表现出色,在计算资源减少4倍的情况下,超过最先进的CNN。 紧接着,2021年,OpenAI连仍两颗炸弹,发布了基于Transformer打造的DALL-E,还有CLIP。 图片 这两个模型借助Transformer实现了很好的效果。DALL-E能够根据文字输出稳定的图像。而CLIP能够实现图像与文本的分类。 再到后来的DALL-E进化版DALL-E 2,还有Stable Diffusion,同样基于Transformer架构,再次颠覆了AI绘画。 以下,便是基于Transformer诞生的模型的整条时间线。 图片 由此可见,Transformer是有多么地能打。
Transformer八子全都叛逃了谷歌。
爆料称,当年参与谷歌Transformer惊世之作的最后一位共同作者Llion Jones,月底将离职谷歌自行创业。
 图片
图片
前谷歌大脑、前Stability AI高管David Ha也转发了这一消息。
2017年6月,「Attention Is All You Need」一声炸雷,大名鼎鼎的Transformer横空出世。
然而,6年过去了,曾联手打造最强架构的「变形金刚们」纷纷离开谷歌,有的加入了OpenAI等初创公司,有的则白手起家去创业。
如今,其中已经确定Transformer七子现在都在哪家公司,唯独Llion Jones一直还留在谷歌。
 图片
图片
而现在,Llion Jones的离去,标志着Transformer「变形金刚大解体」。
作为Transformer架构奠基架构合著者之一,Llion Jones向彭博确认,将于本月晚些时候离开谷歌日本,并计划在休假后创办一家公司。
 图片
图片
Jones在给彭博社的一封消息中写道:
离开谷歌并不是一个容易的决定,我与他们度过了非常精彩的十年,但是现在是尝试一些不同的事情的时候了。鉴于人工智能领域的势头和进展,现在是构建新事物的好时机。
谷歌的一位发言人没有立即回应置评请求。
根据个人领英主页,Llion Jones于2015年6月加入了谷歌,至今已经任职8年。此前他曾就职于YouTube、Delcam。
 图片
图片
他曾在伯明翰大学取得了和计算机专业的学士和硕士学位。
到目前为止,Jones的谷歌学术主页中, 引用最高的一篇文章当属17年横空出世的「Attention Is All You Need」,引用数81266。
 图片
图片
Transformer现在是大型语言模型的关键组成部分,而这种技术是OpenAI的ChatGPT等流行人工智能产品的基础。
在过去的几年中,该论文的作者们已经创办了一些知名的初创企业,包括为企业客户提供LLM的Cohere,以及允许用户创建模仿名人和历史人物的聊天机器人的Character.AI。
随着Jones的离开,意味着所有八位作者都已经离开了谷歌。
那么,其他七子现又身处何处呢?
Jakob Uszkoreit被公认是Transformer架构的主要贡献者。
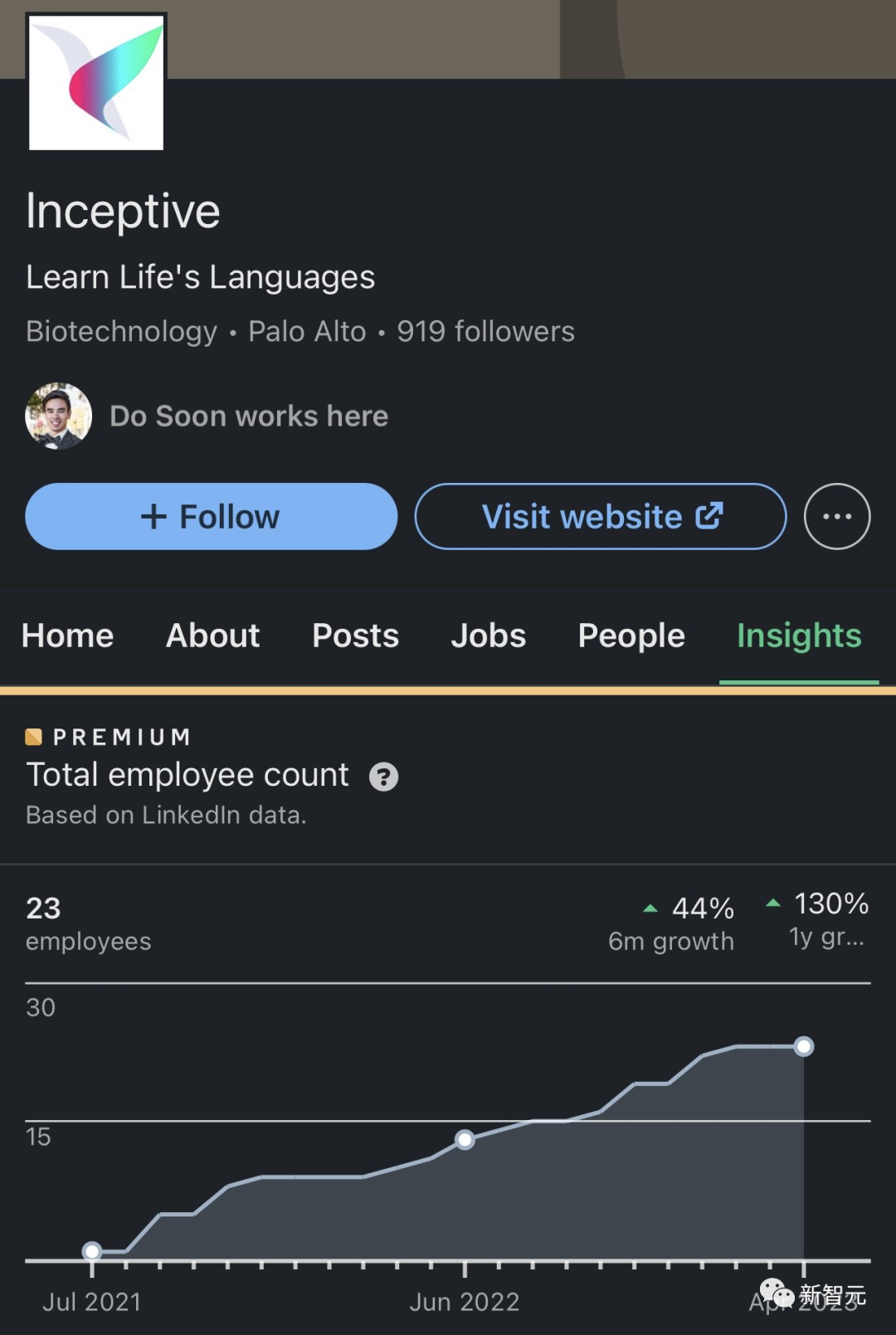
他在2021年中离开了谷歌,并共同创立了Inceptive Labs,致力于使用神经网络设计mRNA。
到目前为止,他们已经筹集了2000万美元,并且团队规模也超过了20人。
 图片
图片
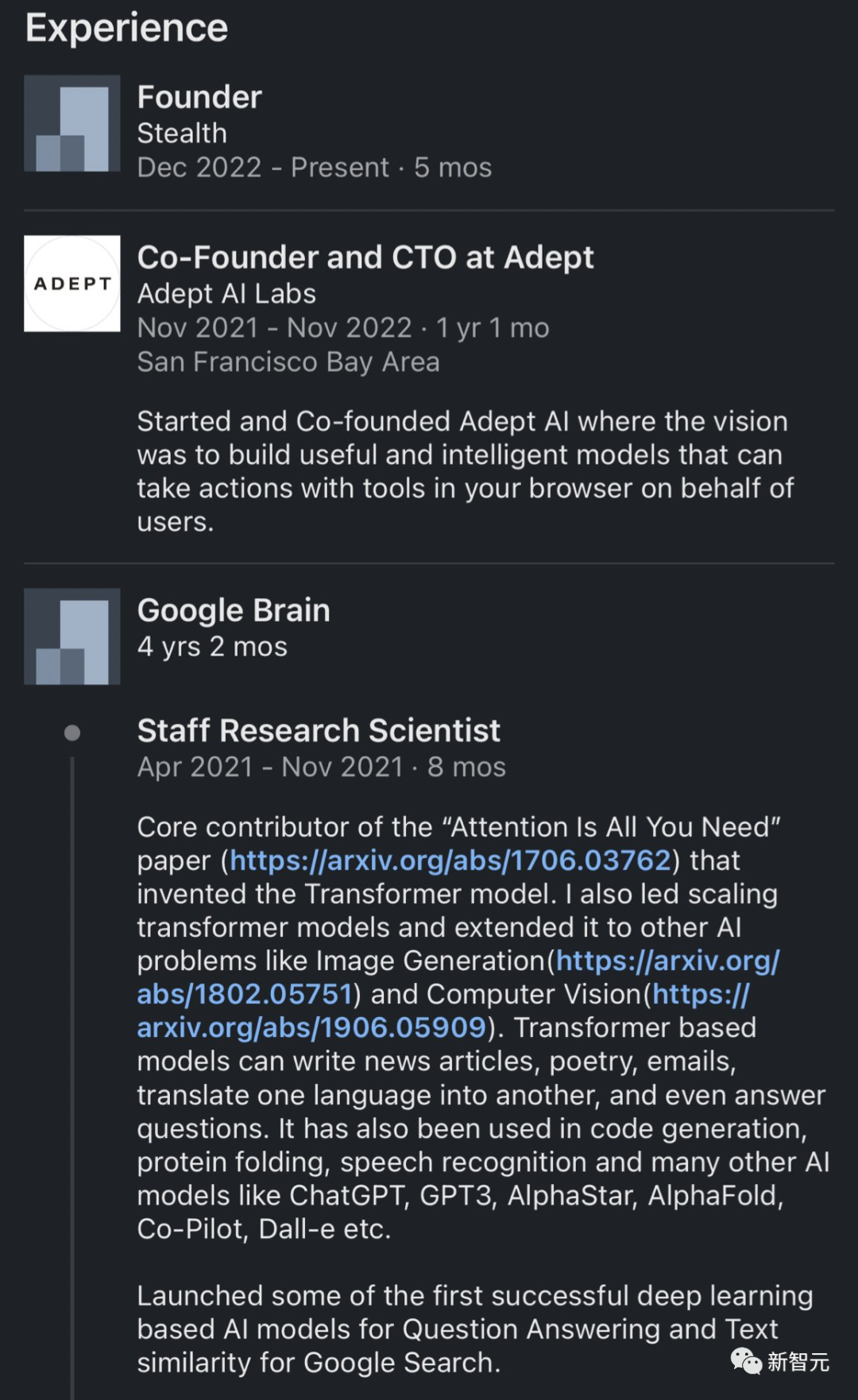
Ashish Vaswani在2021年底离开谷歌,创立了AdeptAILabs。

可以说,AdeptAILabs正处在高速发展的阶段。
目前,公司不仅已经筹集了4.15亿美元,而且也估值超过了10亿美元。
此外,团队规模也刚刚超过了40人。

然而,Ashish却在几个月前离开了Adept。

在Transformers论文中,Niki Parmar是唯一的女性作者。
她在2021年底离开谷歌,并和刚刚提到的Ashish Vaswani一起,创立了AdeptAILabs。
不过,Niki在几个月前也离开了Adept。
Noam Shazeer在Google工作了20年后,于2021年底离开了Google。

随后,他便立刻与自己的朋友Dan Abitbol一起,创立了Character AI。
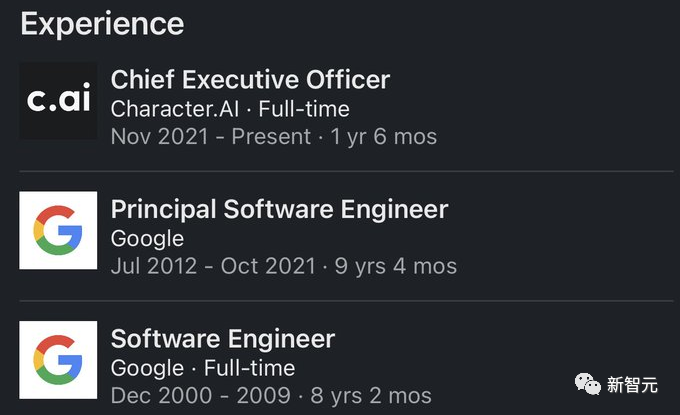
虽然公司只有大约20名员工,但效率却相当之高。
目前,他们已经筹集了近2亿美元,并即将跻身独角兽的行列。


Aidan Gomez在2019年9月离开了Google Brain,创立了CohereAI。


经过3年的稳定发展后,公司依然正在扩大规模——Cohere的员工数量最近超过了180名。
与此同时,公司筹集到的资金也即将突破4亿美元大关。


Lukasz Kaiser是TensorFlow的共同作者人之一,他在2021年中离开了谷歌,加入了OpenAI。

Illia Polosukhin在2017年2月离开了谷歌,于2017年6月创立了NEAR Protocol。

目前,NEAR估值约为20亿美元。
与此同时,公司已经筹集了约3.75亿美元,并进行了大量的二次融资。


Transformer诞生之前,AI圈的人在自然语言处理中大都采用基于RNN(循环神经网络)的编码器-解码器(Encoder-Decoder)结构来完成序列翻译。
然而,RNN及其衍生的网络最致命的缺点就是慢。关键问题就在于前后隐藏状态的依赖性,无法实现并行。
Transformer的现世可谓是如日中天,让许多研究人员开启了追星之旅。
2017年,8位谷歌研究人员发表了Attention is All You Need。可以说,这篇论文是NLP领域的颠覆者。
论文地址:https://arxiv.org/pdf/1706.03762.pdf
它完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,进而实现了并行计算。
甚至,有人发问「有了Transformer框架后是不是RNN完全可以废弃了?」
 图片
图片
JimFan所称Transformer当初的设计是为了解决翻译问题,毋庸置疑。
谷歌当年发的博客,便阐述了Transformer是一种语言理解的新型神经网络架构。
 图片
图片
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
具体来讲,Transformer由四部分组成:输入、编码器、解码器,以及输出。
输入字符首先通过Embedding转为向量,并加入位置编码(Positional Encoding)来添加位置信息。
然后,通过使用多头自注意力和前馈神经网络的「编码器」和「解码器」来提取特征,最后输出结果。

如下图所示,谷歌给出了Transformer如何用在机器翻译中的例子。
机器翻译的神经网络通常包含一个编码器,在读取完句子后生成一个表征。空心圆代表着Transformer为每个单词生成的初始表征。
然后,利用自注意力,从所有其他的词中聚合信息,在整个上下文中为每个词产生一个新表征,由实心圆表示。
接着,将这个步骤对所有单词并行重复多次,依次生成新的表征。
 图片
图片
同样,解码器的过程与之类似,但每次从左到右生成一个词。它不仅关注其他先前生成的单词,还关注编码器生成的最终表征。
2019年,谷歌还专门为其申请了专利。
 图片
图片
自此,在自然语言处理中,Transformer逆袭之路颇有王者之风。
归宗溯源,现在各类层出不穷的GPT(Generative Pre-trained Transformer),都起源于这篇17年的论文。

然而,Transformer燃爆的不仅是NLP学术圈。
2017年的谷歌博客中,研究人员曾对Transformer未来应用潜力进行了畅享:
不仅涉及自然语言,还涉及非常不同的输入和输出,如图像和视频。
 图片
图片
没错,在NLP领域掀起巨浪后,Transformer又来「踢馆」计算机视觉领域。甚至,当时许多人狂呼Transformer又攻下一城。
自2012年以来,CNN已经成为视觉任务的首选架构。
随着越来越高效的结构出现,使用Transformer来完成CV任务成为了一个新的研究方向,能够降低结构的复杂性,探索可扩展性和训练效率。
2020年10月,谷歌提出的Vision Transformer (ViT),不用卷积神经网络(CNN),可以直接用Transformer对图像进行分类。
 图片
图片
值得一提的是,ViT性能表现出色,在计算资源减少4倍的情况下,超过最先进的CNN。
紧接着,2021年,OpenAI连仍两颗炸弹,发布了基于Transformer打造的DALL-E,还有CLIP。
 图片
图片
这两个模型借助Transformer实现了很好的效果。DALL-E能够根据文字输出稳定的图像。而CLIP能够实现图像与文本的分类。
再到后来的DALL-E进化版DALL-E 2,还有Stable Diffusion,同样基于Transformer架构,再次颠覆了AI绘画。
以下,便是基于Transformer诞生的模型的整条时间线。
 图片
图片
由此可见,Transformer是有多么地能打。
© 版权声明
文章版权归作者所有,未经允许请勿转载。








