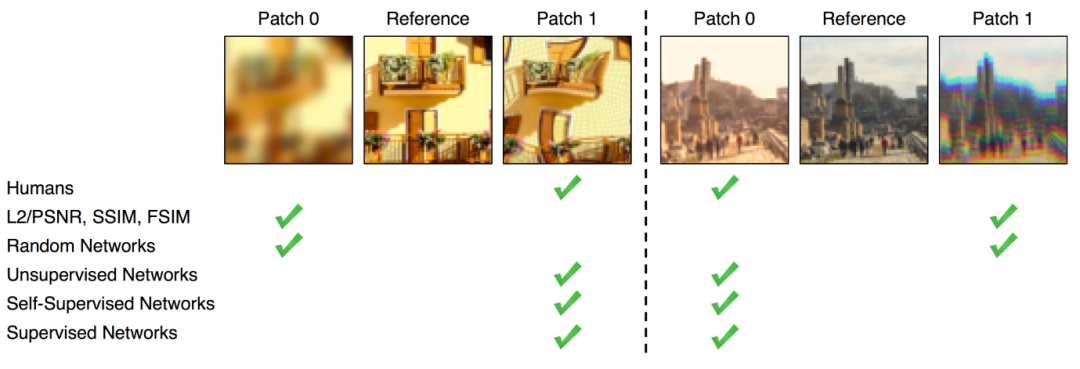
颠覆三观!谷歌最新研究:用性能差的模型计算「相似度」反而更准? 计算图像之间的相似度是计算机视觉中的一个开放性问题。 在图像生成火遍全球的今天,如何定义「相似度」,也是评估生成图像真实度的关键问题。 虽然当下有一些相对直接的方法来计算图像相似度,比如测量像素上的差... 人工智能# 模型 3年前300
你真的正确实现了领域模型吗? 你的代码真的正确实现领域模型了吗?这个题目从领域驱动设计实践者的角度来看,多少有些模糊不清了。代码?领域模型?根据Eric Evans的《Domain-Driven Design》一书,代码本身不也是... 网站建设# eric# evans# 代码 5年前300
调LLaMA类模型没那么难,LoRA将模型微调缩减到几小时 最近几个月,ChatGPT 等一系列大语言模型(LLM)相继出现,随之而来的是算力紧缺日益严重。虽然人人都想打造专属于自己的大模型,但是能负担得起上亿参数模型训练的机构却寥寥无几。 在快速发展的人工智... 人工智能# 模型 3年前290
识别「ChatGPT造假」,效果超越OpenAI:北大、华为的AI生成检测器来了 随着生成式大模型的不断进步,它们生成的语料正逐步逼近人类。虽然大模型正在解放无数文书的双手,它以假乱真的强劲能力也为一些不法分子所利用,造成了一系列社会问题: 来自北大、华为的研究者们提出了一种识别各... 人工智能# 模型 3年前290
连GPT-4都考不及格,17个大模型悉数落败,因果推理太难了 自 ChatGPT 发布以来,大模型的涌现能力一直被人们称赞,包括强大的语言理解能力、生成能力、逻辑推理能力等。然而,最近一项研究表明,大模型在因果推理方面普遍性能很差,连 GPT-4 都不及格。 这... 人工智能# 模型 3年前290
开挖扩散模型小动作,生成图像几乎原版复制训练数据,隐私要暴露了 去噪扩散模型是一类新兴的生成神经网络,通过迭代去噪过程从训练分布中生成图像。与之前的方法(如 GANs 和 VAEs)相比,这类扩散模型产生的样本质量更高,且更容易扩展和控制。因此,经过快速发展,它们... 人工智能# 模型 3年前290
最近大火的Diffusion Model,首篇扩散生成模型综述! 本综述(Diffusion Models: A Comprehensive Survey of Methods and Applications)来自加州大学&Google Research的... 人工智能# 模型 3年前290
多模态图像合成与编辑这么火,马普所、南洋理工等出了份详细综述 近期 OpenAI 发布的 DALLE-2 和谷歌发布的 Imagen 等实现了令人惊叹的文字到图像的生成效果,引发了广泛关注并且衍生出了很多有趣的应用。而文字到图像的生成属于多模态图像合成与编辑领域... 人工智能# 模型 3年前290
逆转特征让re-id模型从88.54%到0.15% 这篇文章初版2018年5月就写好了,最近2022年12月才中。四年中得到了老板们的很多支持和理解。 (这段经历也希望给在投稿的同学们一点鼓舞,paper写好肯定能中的,不要轻易放弃!) arXiv早期... 人工智能# 模型 3年前280
用GPT-4实现可控文本图像生成,UC伯克利&微软提出新框架Control-GPT 文本到图像生成领域近两年取得了很大的突破,从 GAN 到 Stable Diffusion,图像生成的速度越来越快,生成效果越来越好。然而,AI 模型生成的图像在细节上还有很多瑕疵,并且使用自然语言指... 人工智能# 模型 3年前280
统治扩散模型的U-Net要被取代了,谢赛宁等引入Transformer提出DiT 近几年,在 Transformer 的推动下,机器学习正在经历复兴。过去五年中,用于自然语言处理、计算机视觉以及其他领域的神经架构在很大程度上已被 transformer 所占据。 不过还有许多图像级... 人工智能# 模型 3年前280
100亿参数的语言模型跑不动?MIT华人博士提出SmoothQuant量化,内存需求直降一半,速度提升1.56倍! 大型语言模型(LLM)虽然性能强劲,但动辄几百上千亿的参数量,对计算设备还是内存的需求量之大,都不是一般公司能承受得住的。 量化(Quantization)是常见的压缩操作,通过降低模型权重的精度(如... 人工智能# 模型 3年前280
如何将一个算法模型转换成端智能模型? 在开始端智能技术工程实践的介绍前,有一个无法绕过的问题:端上的计算能力到底如何?虽然我们对神经网络运算加速有所耳闻,也知道不同的移动设备有着不同的加速方案,但没有一个定量的分析很难让我们有一个清晰客观... 人工智能# 模型 3年前280
普林斯顿陈丹琦:如何让「大模型」变小 “Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large mode... 人工智能# 模型 3年前280
面试官:说一下Java的共享内存模型 目前正在出一个Java多线程专题长期系列教程,从入门到进阶含源码解读, 篇幅会较多, 喜欢的话,给个关注️ ~ 本篇内容篇纯理论一点,我们之前给大家讲了多线程的一些知识,首先我们要知道的是在并发编程模... 网站建设# java# 多线程# 并发 4年前280
让大学生跑语言大模型,这场世界超算竞赛刚结束,北大首次夺冠 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 第十届ASC世界大学生超算竞赛总决赛,终于在中国科学技术大学落下帷幕。 北京大学首次获得ASC决赛冠军,而东道主中国科学技... 人工智能# 模型 3年前270
高达3.6万亿token!PaLM 2训练数据翻5倍,全新Bard对比ChatGPT有8个优势 决定大模型能力的关键因素,到底是模型的参数,还是训练文本的大小? 谷歌发布的PalM2,似乎选择了后者作为提升的主要路径。 据悉,谷歌用于训练的PaLM2的文本数量几乎是训练其前身模型的5倍。 而且上... 人工智能# 模型 3年前270
130亿参数,8个A100训练,UC伯克利发布对话模型Koala 自从 Meta 发布并开源了 LLaMA 系列模型,来自斯坦福大学、UC 伯克利等机构的研究者们纷纷在 LLaMA 的基础上进行「二创」,先后推出了 Alpaca、Vicuna 等多个「羊驼」大模型... 人工智能# 模型 3年前270
ControlNet大更新:仅靠提示词就能精准P图,保持画风不变,网友:效果堪比定制大模型 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 Stable Diffusion插件、“AI绘画细节控制大师”ControlNet迎来重磅更新: 只需使用文本提示词,就能... 人工智能# 模型 3年前270
证件照转数字人只需几秒钟,微软实现首个3D扩散模型高质量生成效果,换装改形象一句话搞定 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 一张2D证件照,几秒钟就能设计出3D游戏化身! 这是扩散模型在3D领域的最新成果。例如,只需一张法国雕塑家罗丹的旧照,就能... 人工智能# 模型 3年前270
11分钟训完GPT-3!英伟达H100 横扫MLPerf 8项基准测试,下一代显卡25年发布 最新MLPerf训练基准测试中,H100 GPU在所有的八项测试中都创下了新纪录! 如今,NVIDIA H100几乎已经统治了所有类别,并且是新LLM基准测试中使用的唯一 的GPU。 图片 3,584... 人工智能# 模型 3年前270
ConvNeXt V2来了,仅用最简单的卷积架构,性能不输Transformer 经过几十年的基础研究,视觉识别领域已经迎来了大规模视觉表征学习的新时代。预训练的大规模视觉模型已经成为特征学习(feature learning)和视觉应用的基本工具。视觉表征学习系统的性能在很大程度... 人工智能# 模型 3年前270
脑补出新视角,一个统一的NeRF代码库框架已开源 假设一个物体你看了几张照片后,能想象出其它角度看上去的感觉吗?人是可以做到的,我们能自行推测出没见过的部分,或者说没见过的角度是什么样的。模型其实也有办法做到,给定一些场景图片,它也能脑补出一些未见过... 人工智能# 模型 3年前270
CLIP不接地气?你需要一个更懂中文的模型 本文介绍的是达摩院魔搭社区 ModelScope 近期开源的中文 CLIP 大规模预训练图文表征模型,更加懂中文和中文互联网的图像,在图文检索、零样本图片分类等多个任务中实现最优效果,同时代码和模型已... 人工智能# 模型 3年前270
推理速度比Stable Diffusion快2倍;视觉Transformer统一图像文本 论文 1:One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations ... 人工智能# 模型 3年前270
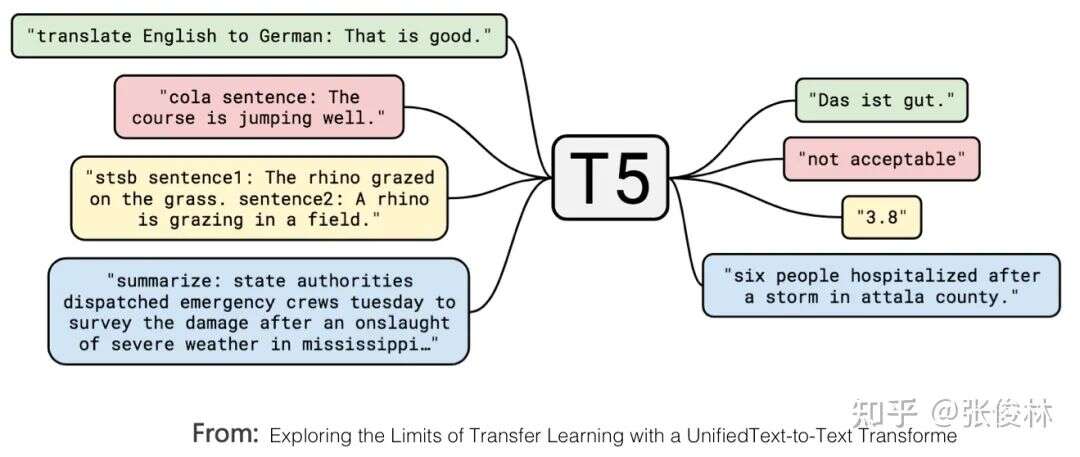
基于谷歌T5模型细调大型语言模型 译者 | 朱先忠,审校 | 孙淑娟,还记得第一次开始构建一些SQL查询来分析数据吗?相信大多数时候,你只是想看看“有哪些畅销产品”或“每周产品访问次数”。那么,为什么要编写SQL查询,而不只是用自然语... 网站建设# language# sql# text 4年前270
python模型集成是什么 ,说明,1、模型集成是指将一系列不同模型的预测结果集成在一起,从而获得更好的预测结果。,2、对于模型集成来说,模型的多样性非常重要。Diversityisstrength.用于集成的模型应尽可能好,同... 网站建设# python# 不同# 更好 4年前270
开启 DevOps之旅,有哪些关键点? ,想要落地DevOps却不知道如何入手?本篇文章将带你深入学习关于DevOps的关键概念及优秀实践。,,一般认为,DevOps的出现源于两个因素:敏捷软件方法的广泛采用以及IT基础设施及代码的管理方式... 网站建设# devops# 方法# 模型 4年前270
将26个token压缩成1个,新方法极致节省ChatGPT输入框空间 进入正文之前,先考虑一下像 ChatGPT 这样的 Transformer 语言模型(LM)的 prompt: 随着每天产生数百万用户和查询,ChatGPT 使用自注意力机制对 prompt 进行反复... 人工智能# 模型 3年前260
谷歌推出多模态Vid2Seq,理解视频IQ在线,字幕君不会下线了|CVPR 2023 最近,来自谷歌的研究员提出了一种用于描述多事件视频的预训练视觉语言模型——Vid2Seq,目前已被CVPR23接收。 在以前,理解视频内容是一项具有挑战性的任务,因为视频通常包含在不同时间尺度发生的多... 人工智能# 模型 3年前260
分割一切深度图!港科技、南洋理工等开源「SAD」:根据几何信息分割图像 本月初,Meta推出的一款可以「分割一切」的模型Segment Anything Model (SAM) 已经引起了广泛的关注。今天,我们向大家介绍一款名为「Segment Any RGBD(SAD... 人工智能# 模型 3年前260
幻觉?马斯克TruthGPT也搞不定!OpenAI联合创始人直言很复杂 上个月,马斯克疯狂呼吁叫停超级AI研发6个月。 还没等多久,老马就坐不住了,直接官宣推出一个名为TruthGPT的AI平台。 马斯克曾表示,TruthGPT将是一个「最大的求真人工智能」,它将试图理解... 人工智能# 模型 3年前260
GAN的反击:朱俊彦CVPR新作GigaGAN,出图速度秒杀Stable Diffusion 图像生成是当前 AIGC 领域最热门的方向之一。近期发布的图像生成模型如 DALL・E 2、Imagen、Stable Diffusion 等等,开创了图像生成的新时代,实现了前所未有的图像质量和模型... 人工智能# 模型 3年前260
首次:微软用GPT-4做大模型指令微调,新任务零样本性能再提升 我们知道,从谷歌 T5 模型到 OpenAI GPT 系列大模型,大语言模型(LLMs)已经展现出了令人印象深刻的泛化能力,比如上下文学习和思维链推理。同时为了使得 LLMs 遵循自然语言指令和完成真... 人工智能# 模型 3年前260
成本不到100美元!UC伯克利再开源类ChatGPT模型「考拉」:数据量大没有用,高质量才是王道 自从Meta开源LLaMA之后,学术界内各种类ChatGPT模型如雨后春笋般开始发布。先是斯坦福提出了70亿参数Alpaca,紧接着又是UC伯克利联手CMU、斯坦福、UCSD和MBZUAI发布的130... 人工智能# 模型 3年前260
首个目标检测扩散模型,比Faster R-CNN、DETR好,从随机框中直接检测 扩散模型( Diffusion Model )作为深度生成模型中的新 SOTA,已然在图像生成任务中超越了原 SOTA:例如 GAN,并且在诸多应用领域都有出色的表现,如计算机视觉,NLP、分子图建模... 人工智能# 模型 3年前260
AI降维打击人类画家,文生图引入ControlNet,深度、边缘信息全能复用 随着大型文本 - 图像模型的出现,生成一幅吸引人的图像已经变得非常简单,用户需要做的就是动动手指输入简单的 prompt 就可以。通过一系列操作得到图像后,我们不免又会产生这样几个问题:基于 prom... 人工智能# 模型 3年前260
固定参数的模型有多大潜力?港中文、上海AI Lab等提出高效视频理解框架EVL 视觉基础模型近两年取得了瞩目发展。从一方面而言,基于大规模互联网数据的预训练已经给模型预置了大量的语义概念,从而具有良好的泛化性能;但另一方面,为充分利用大规模数据集带来的模型尺寸增长,使得相关模型在... 人工智能# 模型 3年前260
生成高精细节,新方法AligNeRF解决NeRF对齐问题 虽然 NeRF 能够用不同视角的视图中渲染复杂的 3D 场景,但很少有人致力于探索其在高分辨率设置中的局限性。具体来说,现有的基于 NeRF 的方法在重建高分辨率的真实场景时面临着一些限制,包括大量的... 人工智能# 模型 3年前250
OpenAI CEO:巨型AI模型时代已结束,马斯克TruthGPT曝光 近几个月来,OpenAI ChatGPT 的强大生成式对话能力引发了人们对 AI 的新兴趣和投资。随着国内外掀起类 ChatGPT 研发热潮,对话式 AI 及背后的大模型被更多人看好。 但上周在 MI... 人工智能# 模型 3年前250
用Meta「分割一切」搞定一切关系,唱跳偷袭效果拔群!NTU等提出全新RAM模型 本月初,Meta推出的「分割一切」模型可谓是震撼了整个CV圈。 这几天,一款名为「Relate-Anything-Model(RAM)」的机器学习模型横空出世。它赋予了Segment Anything... 人工智能# 模型 3年前250
LLM推理提速2.8倍,CMU清华姚班校友提出「投机式推理」引擎SpecInfer,小模型撬动大模型高效推理 随着 ChatGPT 的出现,大规模语言模型(LLM)研究及其应用得到学术界和工业界的广泛关注。一方面,开源的 LLM 模型不断涌现,比如 OPT、BLOOM、LLaMA 等,这些预训练模型的推出极大... 人工智能# 模型 3年前250
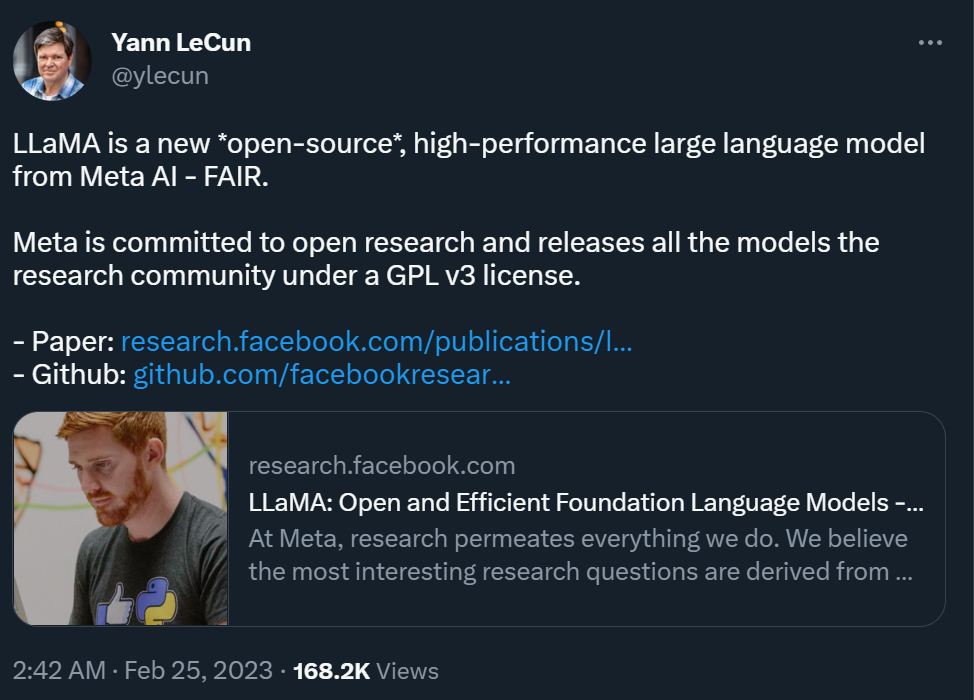
这是Meta版ChatGPT雏形?开源、一块GPU就能跑,1/10参数量打败GPT-3 千亿、万亿参数的超大模型需要有人研究,十亿、百亿参数的大模型同样需要。 刚刚,Meta 首席 AI 科学家 Yann LeCun 宣布,他们「开源」了一个新的大模型系列 ——LLaMA(Large L... 人工智能# 模型 3年前250
打破不可能三角、比肩5400亿模型,IDEA封神榜团队仅2亿级模型达到零样本学习SOTA 自从 GPT-3 问世,展现出千亿级模型的强大实力以来,NLP 任务面临着规模、样本、Fine-tuning 性能的不可能三角。如何在保证 10 亿参数以下的语言模型可以达到 SOTA 的 Few-S... 人工智能# 模型 3年前250
1块GPU+几行代码,大模型训练提速40%!无缝支持HuggingFace 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 不得不说,为了让更多人能用上大模型,技术圈真是各出奇招! 模型不够开放?有人自己上手搞免费开源版。 比如最近风靡全网的DA... 人工智能# 模型 3年前250
CV开启大模型时代!谷歌发布史上最大ViT:220亿参数,视觉感知力直逼人类 Transformer无疑是促进自然语言处理领域繁荣的最大功臣,也是GPT-4等大规模语言模型的基础架构。 不过相比语言模型动辄成千上万亿的参数量,计算机视觉领域吃到Transformer的红利就没那... 人工智能# 模型 3年前240
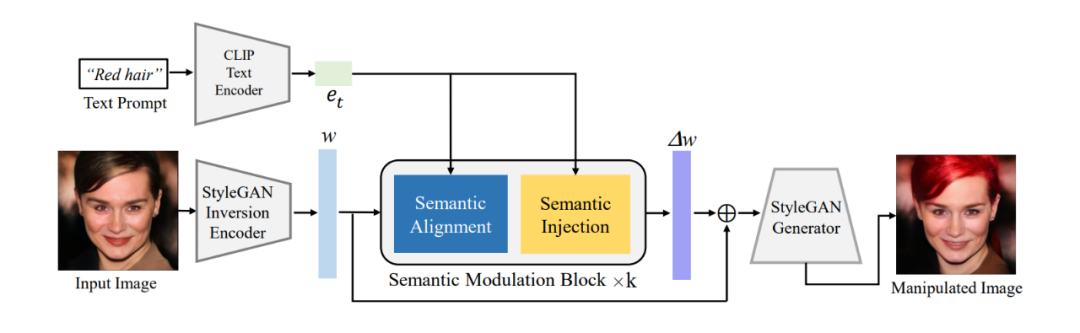
文本图片编辑新范式,单个模型实现多文本引导图像编辑 论文简要概述 利用文本对图像进行编辑的相关研究非常火热,最近许多研究都基于去噪扩散模型来提升效果而少有学者继续关注 GAN 的相关研究。本文基于经典的 StyleGAN 和 CLIP 并提出语义调制模... 人工智能# 模型 3年前240
斯坦福新研究:ChatGPT背后模型被证实具有人类心智 ChatGPT原来是拥有心智的?!“原本认为是人类独有的心智理论(Theory of Mind,ToM),已经出现在ChatGPT背后的AI模型上。” 这是来自斯坦福大学的最新研究结论,一经发出就造成... 人工智能# 模型 3年前240
一颗GPU,秒出3D模型!OpenAI重磅新作:Point-E用文本即可生成三维点云模型 席卷AI世界的下一个突破在哪里? 很多人预测,是3D模型生成器。 继年初推出的DALL-E 2用天才画笔惊艳所有人之后,周二OpenAI发布了最新的图像生成模型「POINT-E」,它可通过文本直接生成... 人工智能# 模型 3年前240
零信任架构:关键原则、组件、优点和缺点 在您的网络中,可以信任谁?在零信任范式中,答案是否定的。网络安全的零信任方法指出,只有在验证用户后才应授予访问权限,并且只能在执行特定任务所需的范围内授予访问权限。,在本文中,我们将详细介绍实现零信任... 网站建设# 信任# 权限# 模型 4年前240
谷歌报复性砸出5620亿参数大模型!比ChatGPT更恐怖,机器人都能用,学术圈已刷屏 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 为应对新一轮技术竞赛,谷歌还在不断出后手。 这两天,一个名叫PaLM-E的大模型在AI学术圈疯狂刷屏。 它能只需一句话,就... 人工智能# 模型 3年前230
阿里版ChatGPT突然上线邀测!大模型热战正剧开始,这是第一手体验实录 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 阿里正式加入ChatGPT战局! 就在刚刚,阿里版类ChatGPT突然官宣正式对外开放企业邀测。 它叫通义千问,由达摩院开... 人工智能# 模型 3年前230
开发者笑疯了! LLaMa惊天泄露引爆ChatGPT平替狂潮,开源LLM领域变天 谁能想到,一次意外的LLaMA泄漏,竟点燃了开源LLM领域最大的创新火花。 一系列表现出色的ChatGPT开源替代品——「羊驼家族」,随后眼花缭乱地登场。 开源和基于 API 的分发之间的摩擦,是生成... 人工智能# 模型 3年前230
Meta开源的ChatGPT平替到底好不好用?测试结果、加料改装方法已出炉,2天5.2k星 ChatGPT 的持续爆火,早已让各大科技公司坐不住了。 就在刚刚过去的一周,Meta「开源」了一个新的大模型系列 ——LLaMA(Large Language Model Meta AI... 人工智能# 模型 3年前220
时序分析五边形战士!清华提出TimesNet:预测、填补、分类、检测全面领先 实现任务通用是深度学习基础模型研究的核心问题,也是近期大模型方向的主要关注点之一。 然而,在时间序列领域,各类分析任务的差别较大,既有需要细粒度建模的预测任务,也有需要提取高层语义信息的分类任务。如何... 人工智能# 模型 3年前220
如何正确定义测试阶段训练?顺序推理和域适应聚类方法 域适应是解决迁移学习的重要方法,当前域适应当法依赖原域和目标域数据进行同步训练。当源域数据不可得,同时目标域数据不完全可见时,测试阶段训练(Test- Time Training)成为新的域适应方法... 人工智能# 模型 3年前220
又是一年跳槽季!Nginx 十道核心面试题及解析 ,Nginx是一款轻量级的高性能Web服务器和反向代理服务器,由俄罗斯的Igor Sysoev开发。它具有占用资源少、高并发、稳定性高等优点,被广泛应用于互联网领域。在Nginx的面试过程中,面试官通... 网站建设# nginx# 代理服务器# 并发 4年前220
给语言大模型加上综合视听能力,达摩院开源Video-LLaMA 视频在当今社交媒体和互联网文化中扮演着愈发重要的角色,抖音,快手,B 站等已经成为数以亿计用户的热门平台。用户围绕视频分享自己的生活点滴、创意作品、有趣瞬间等内容,与他人互动和交流。 近期,大语言模型... 人工智能# 模型 3年前210
PromptPG:当强化学习遇见大规模语言模型 数学推理是人类智能的一项核心能力,但对于机器来说,抽象思维和逻辑推理仍然是一个很大的挑战。大规模预训练语言模型,如 GPT-3 和 GPT-4,在文本形式的数学推理(如数学应用题)上已经取得了显著的进... 人工智能# 模型 3年前210
24小时内、200美元复制RLHF过程,斯坦福开源「羊驼农场」 2 月底,Meta 开源了一个大模型系列 LLaMA(直译为羊驼),参数量从 70 亿到 650 亿不等,被称为 Meta 版 ChatGPT 的雏形。之后斯坦福大学、加州大学伯克利分校等机构纷纷在 ... 人工智能# 模型 3年前210
清华朱军团队开源首个基于Transformer的多模态扩散大模型,文图互生、改写全拿下 据悉 GPT-4 将于本周发布,多模态将成为其一大亮点。当前的大语言模型正在成为理解各种模态的通用接口,能够根据不同模态信息来给出回复文本,但大语言模型生成的内容也仅仅局限于文本。另一方面,当前的扩散... 人工智能# 模型 3年前210
单GPU实现20Hz在线决策,最新基于序列生成模型的高效轨迹规划方法解读 之前我们介绍了基于 Transformer 和扩散模型(Diffussion Model)的序列建模(sequence modelling)方法在强化学习,特别是离线连续控制领域的应用。这其中 Tra... 人工智能# 模型 3年前210
首个大规模使用工具的大模型来了:伯克利发布Gorilla 大型语言模型性能强大,但为了更好地用于解决实际问题,各式各样的 API 是必不可少的。 近日,加利福尼亚大学伯克利分校和微软研究院造出了一只「大猩猩」Gorilla,该模型能根据用户输入的自然语言为用... 人工智能# 模型 3年前200
跑ChatGPT体量模型,从此只需一块GPU:加速百倍的方法来了 计算成本是人们打造 ChatGPT 等大模型面临的重大挑战之一。 据统计,从 GPT 进化到 GPT-3 的过程也是模型体量增长的过程 —— 参数量从 1.17 亿增加到了 1750 亿,预训练数据量... 人工智能# 模型 3年前200
直面图的复杂性,港中文等提出面向图数据分布外泛化的因果表示学习 随着深度学习模型的应用和推广,人们逐渐发现模型常常会利用数据中存在的虚假关联(Spurious Correlation)来获得较高的训练表现。但由于这类关联在测试数据上往往并不成立,因此这类模型的测试... 人工智能# 模型 3年前200
Meta推出MoDem世界模型:解决视觉领域三大挑战,LeCun转发 12月27日,MetaAI 负责视觉和强化学习领域的A 截止27日晚间,这篇推文的阅读量已经达到73.9k。 他表示,仅给出5个演示,MoDem就能在100K交互步骤中解决具有稀疏奖励和高维动作空间的... 人工智能# 模型 3年前200
基于对抗梯度的探索模型及其在点击预估中的应用 1. 摘要 排序模型在广告、推荐和搜索系统中起到了至关重要的作用。在排序模块中,点击率预估技术又是重中之重。目前工业界的点击率预估技术大多采用深度学习算法,基于数据驱动来训练深度神经网络,然而数据驱动... 人工智能# 模型 3年前200
超越所有开源模型,击败 Claude、Bard,专门用于编程任务的大模型来了 最近一段时间,随着大语言模型(LLM)的不断发布,LLM 排位赛也变得火热起来,研究者们试图在新的 LLM 评测系统中不断刷新自家模型的分数。 在这当中,斯坦福发布的全新大语言模型排行榜 Alpaca... 人工智能# 模型 3年前190
大语言模型做数据助手,浙大Data-Copilot高效调用、处理、可视化数据 金融、气象、能源等各行各业每天都会生成大量的异构数据。人们急切需要一个工具来有效地管理、处理和展示这些数据。 近日,浙江大学提出 DataCopilot,通过部署大语言模型 (LLMs) 来自主地管理... 人工智能# 模型 3年前190
稀疏模型最新进展!马毅+LeCun强强联手:「白盒」非监督式学习 最近马毅教授和图灵奖得主Yann LeCun联手在ICLR 2023上发表了一篇论文,描述了一种极简和可解释的非监督式学习方法,不需要求助于数据增强、超参数调整或其他工程设计,就可以实现接近 SOTA... 人工智能# 模型 3年前190
斯坦福博士生自制PPT生成神器ChatBCG免费开放!一键生成自定义模版,还能导出PDF 相信不管是学生党,还是上班族,都有为PPT汇报熬夜爆肝的经历...... 光挑选模版和样式就杀死了一堆脑细胞。 而现在,一款能一键自动生成PPT模版和文字可能成为解放生产力的神器,它就是ChatBCG... 人工智能# 模型 3年前190
真的这么丝滑吗?Hinton组提出基于大型全景掩码的实例分割框架,图像视频场景丝滑切换 全景分割是一项基本的视觉任务,该任务旨在为图像的每个像素指定语义标签和实例标签。语义标签描述每个像素的类别(例如天空、竖直物体等),实例标签为图像中的每个实例提供唯一的 ID(以区分同一类别的不同实例... 人工智能# 模型 3年前190
图片迟迟加载不了、一片马赛克?谷歌开源模型优先显示图像受关注部分 当观察一副图像时,你会先注意图像的哪些内容,或者说图像中的哪些区域会首先吸引你的注意力,机器能否学会人类的这种注意力形式。在来自谷歌的一项研究中,他们开源的注意力中心模型(attention cent... 人工智能# 模型 3年前190
只需3个样本一句话,AI就能定制照片级图像,谷歌在玩一种很新的扩散模型 近来,文本到图像模型成为一个热门的研究方向,无论是自然景观大片,还是新奇的场景图像,都可能使用简单的文本描述自动生成的。 其中,渲染天马行空的的想象场景是一项具有挑战性的任务,需要在新的场景中合成特定... 人工智能# 模型 3年前190
预训练无需注意力,扩展到4096个token不成问题,与BERT相当 Transformer 作为 NLP 预训练模型架构,能够有效的在大型未标记的数据上进行学习,研究已经证明,Transformer 是自 BERT 以来 NLP 任务的核心架构。 最近的工作表明,状态... 人工智能# 模型 3年前190
第一家濒临倒闭的AI绘画创业公司出现了,创始人:根本赚不到钱 2022 年的 AIGC 创业,可以说是冰火两重天。 有人融了 1.01 亿美元,两年时间就打造了一家独角兽公司,估值近 10 亿美元。 有人创立公司仅四个月,就已经预感到了「倒闭」的危险。 就在前几... 人工智能# 模型 3年前190
同济、阿里的CVPR 2022最佳学生论文奖研究了什么?这是一作的解读 本文解读我们获得 CVPR 2022 最佳学生论文奖的工作《EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points fo... 人工智能# 模型 3年前190
无需RLHF就能对齐人类,性能比肩ChatGPT!华人团队提出袋熊Wombat模型 OpenAI的ChatGPT能够理解各种各样的人类指令,并在不同的语言任务中表现出色。这归功于一种新颖的大规模语言模型微调方法——RLHF(通过强化学习对齐人类反馈)。 RLHF方法解锁了语言模型遵循... 人工智能# 模型 3年前180
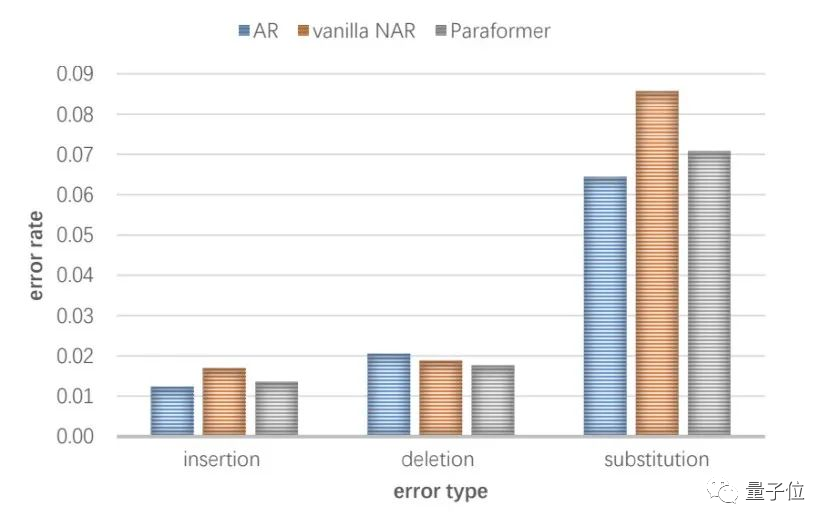
阿里「杀手锏」级语音识别模型来了!推理效率较传统模型提升10倍,已开源 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 阿里达摩院,又搞事儿了。 这两天,它们发布了一个全新的语音识别模型: Paraformer。 开发人员直言不讳:这是我们... 人工智能# 模型 3年前180
北大河图发布分布式训练神器Galvatron, 一键实现大模型高效自动并行 最近一段时间,「大模型」在 AI 领域的各种应用场景都大放异彩,其中基于 Transformer 的大规模预训练模型是最典型的大模型之一,已经成为了当前基础模型(Foundation Model)的核... 人工智能# 模型 3年前180
时间序列也能和大模型结合?亚马逊最新工作,大模型可解释时序预测 这几天亚马逊发布了一篇使用大模型做时间序列预测的工作,属于大模型在时序预测中的第一次探索,利用大模型提升金融场景预测中的多模态数据处理能力和可解释能力。这篇文章属于一个比较有意思的探索工作,思路可以借... 人工智能# 模型 3年前170
一键生成山川、河流,风格多样,从2D图像中学习生成无限3D场景 项目主页:https://scene-dreamer.github.io/ 代码:https://github.com/FrozenBurning/SceneDreamer 论文:https://ar... 人工智能# 模型 3年前170
这种精度高,消耗资源少的大模型稀疏训练方法被找到了 近日,阿里云机器学习PAI关于大模型稀疏训练的论文《Parameter-Efficient Sparsity for Large Language Models Fine-Tuning》被人工智能顶会... 人工智能# 模型 3年前170
必应发狂了! LeCun马库斯齐喷ChatGPT:大语言模型果然是邪路? 马库斯和LeCun忽然就握手言和、统一战线了? 这可奇了,两人过去一向是死对头,在推特和博客上你来我往的骂战看得瓜众们是啧啧称奇。 恭喜LeCun,你终于站到了正确的一边。 其实,这件事是有背景的... 人工智能# 模型 3年前170
推理速度比Stable Diffusion快2倍,生成、修复图像谷歌一个模型搞定,实现新SOTA 文本到图像生成是 2022 年最火的 AIGC 方向之一,被《science》评选为 2022 年度十大科学突破。最近,谷歌的一篇文本到图像生成新论文《Muse: Text-To-Image Gene... 人工智能# 模型 3年前170
生成式语义分割新范式GMMSeg,可同时处理闭集和开集识别 当前主流语义分割算法本质上是基于 softmax 分类器的判别式分类模型,直接对 p (class|pixel feature) 进行建模,而完全忽略了潜在的像素数据分布,即 p (class|pix... 人工智能# 模型 3年前170
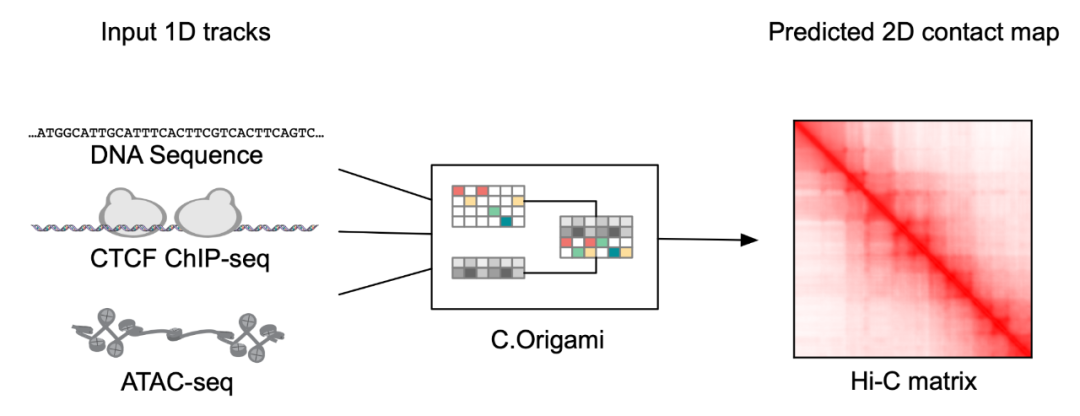
谭济民、夏波等提出基因组构象预测模型及高通量计算遗传筛选方法 图 0 不同种类细胞中基因组构象的差异决定了基因表达的特异性,进而决定不同细胞类型的功能差异。长久以来,从原位杂交到高通量检测如 Hi-C、micro-C 技术,基因组构象检测的实验方法通常耗时耗力... 人工智能# 模型 3年前170
从单幅自然图像学习扩散模型,优于GAN,SinDiffusion实现新SOTA 从单幅自然图像生成图像的技术被广为应用,也因此受到越来越多的关注。这一研究旨在从单幅自然图像中学习一个无条件生成模型,通过捕获 patch 内部统计信息,生成具有相似视觉内容的不同样本。一旦训练完成... 人工智能# 模型 3年前170
谷歌、MIT「迭代共同认证」视频问答模型:SOTA性能,算力少用80% 视频是一种无处不在的媒体内容源,涉及到人们日常生活的许多方面。越来越多的现实世界的视频应用,如视频字幕、内容分析和视频问答(VideoQA),都依赖于能够将视频内容与文本或自然语言联系起来的模型。 ... 人工智能# 模型 3年前170
当「分割一切」遇上图像修补:无需精细标记,单击物体实现物体移除、内容填补、场景替换 4 月初,Meta 发布了史上首个图像分割基础模型--SAM(Segment Anything Model)[1]。作为分割模型,SAM 的能力强大,操作使用方式也十分友好,比如用户简单地点击来选择对... 人工智能# 模型 3年前160
AI模仿人脑记忆模式,游戏成绩大涨29.9% 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 我们常常被教育的做事“三思而后行”,充分运用积累过的经验,现在这句话对AI也有所启发了。 传统的决策AI模型由于遗忘效应的... 人工智能# 模型 3年前160
后GPT 3.0时代,主流大模型技术精要详解,走向AGI之路的大门已开 ChatGPT 出现后惊喜或惊醒了很多人。惊喜是因为没想到大型语言模型(LLM,Large Language Model)效果能好成这样;惊醒是顿悟到我们对 LLM 的认知及发展理念,距离世界最先进的... 人工智能# 模型 3年前160
仅需10%参数量即超越SOTA!浙大、字节、港中文联合提出「类别级位姿估计」任务新框架 赋予机器人对日常物体的 3D 理解是机器人应用中的一项重大挑战。 在未知环境中进行探索时,由于物体形状的多样性,现有的物体位姿估计方法仍然不能令人满意。 最近浙江大学、字节跳动人工智能实验室和香港中文... 人工智能# 模型 3年前160
月之暗面又开源了 登顶全球第一,还超了新版DeepSeek-R1 今日凌晨,月之暗面推出针对软件工程任务的全新开源代码大模型Kimi-Dev-72B。该模型在SWE-bench Verified编程基准测试中取得了全球最高开源模型水平,以仅72B的参数量,成绩超过了... 人工智能# b# bench# swe 10个月前0150
Midjourney「搞怪」炸出!表情包生成器,马斯克变身公主|附教程 Midjourney 5.2发布才一周,又迎来了重大更新! 没想到,新功能「weird」一出,网友们脑洞大开,便在这条路上一发不可收拾。 风格不同搞怪表情包,恐怖大片泉涌,比如这个新版「复仇者联盟... 人工智能# 模型 3年前150
Stable Diffusion背后公司开源大语言模型,很火,但很烂 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 万万没想到,以文生图著名的Stable Diffusion,也入局了大语言模型(LLM)之战。 它背后的公司Stabili... 人工智能# 模型 3年前150
扩散模型和Transformer梦幻联动!一举拿下新SOTA,MILA博士:U-Net已死 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 “U-Net已死,Transformer成为扩散模型新SOTA了!” 就在ChatGPT占尽AI圈风头时,纽约大学谢赛宁的... 人工智能# 模型 3年前150
开源模型、单卡训练,带你了解爆火的文本指导音频生成技术AudioLDM 给出一段文字,人工智能就可以生成音乐,语音,各种音效,甚至是想象的声音,比如黑洞和激光枪。最近由英国萨里大学和帝国理工学院联合推出的AudioLDM,在发布之后迅速火遍国外,一周内在推特上收获了近 3... 人工智能# 模型 3年前150
效率碾压DALL·E 2和Imagen,谷歌新模型达成新SOTA,还能一句话搞定PS 新年伊始,谷歌AI又开始发力文字-图像生成模型了。 这次,他们的新模型Muse(缪斯)在CC3M数据集上达成了新SOTA(目前最佳水平)。 而且其效率远超火爆全球的DALL·E 2和Imagen (这... 人工智能# 模型 3年前150