一份来自Huggingface的大模型进化指南:没有必要完全复现GPT-4 大数据文摘出品 ChatGPT爆火之后,AI界进行了一场“百模大战”。近日,Huggingface的机器学习科学家Nathan Lambert,在一篇博文中对当前入局大模型的力量,从开源视角进行了梳理... 人工智能# 模型 3年前450
多模态如何自监督?爱丁堡等最新「自监督多模态学习」综述:目标函数、数据对齐和模型架构 多模态学习旨在理解和分析来自多种模态的信息,近年来在监督机制方面取得了实质性进展。 然而,对数据的严重依赖加上昂贵的人工标注阻碍了模型的扩展。与此同时,考虑到现实世界中大规模的未标注数据的可用性,自监... 人工智能# 模型 3年前450
视觉卷不动了,来看看分子领域?全球首个分子图像自监督学习框架ImageMol来了 分子是维持物质化学稳定性的最小单位。对分子的研究,是药学、材料学、生物学、化学等众多科学领域的基础性问题。 分子的表征学习(Molecular Representation Learning)是近年来... 人工智能# 模型 3年前450
扩散模型背后数学太难了,啃不动?谷歌用统一视角讲明白了 最近一段时间,AI 作画可谓是火的一塌糊涂。 在你惊叹 AI 绘画能力的同时,可能还不知道的是,扩散模型在其中起了大作用。就拿热门模型 OpenAI 的 DALL·E 2 来说,只需输入简单的文本(p... 人工智能# 模型 3年前450
LeCun高徒超详笔记曝光,Meta世界模型首揭秘!首个「类人」模型怎么来的? LeCun究竟是经过了怎样的思考,才得出了世界模型是AI大模型未来最理想道路的结论? 很幸运,去年曾听过他在暑假学校关于统计物理和机器学习演讲的学生Ania Dawid,将他的观点仔细地整理和发表出来... 人工智能# 模型 3年前440
首个3D人像视频生成模型来了:仅需1张2D人像,眨眼、口型都能改变 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 只需1张普通照片,就能合成全角度动态3D视频。 眨个眼、动动嘴,都是小case~ 最近AIGC爆火,3D人像模型生成这边也... 人工智能# 模型 3年前440
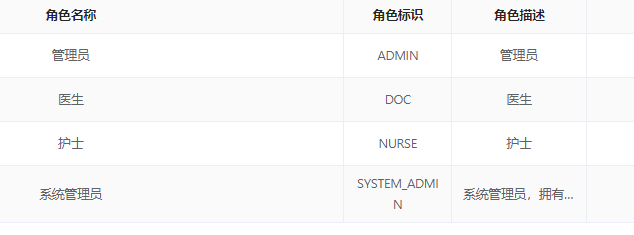
医疗系统的权限就该这样设计,稳! 权限管控可以通俗的理解为权力限制,即不同的人由于拥有不同权力,他所看到的、能使用的可能不一样。对应到一个应用系统,其实就是一个用户可能拥有不同的数据权限(看到的)和操作权限(使用的)。,主流的权限模型... 网站建设# rbac# 权限# 模型 3年前440
一文读懂“语言模型” 自然语言处理(NLP)近年来发生了革命性的变化,特别预训练语言模型的开发和使用,在许多应用方面都取得了显著的成绩。预训练语言模型有两个主要优点:一个是可以显著提高许多 NLP 任务的准确性。例如,可以... 网站建设# nlp# 模型# 自然语言 4年前440
大模型时代,解析周志华教授的「学件」思想:小模型也可做大事 毫无疑问,我们正在进入一个大模型时代,各种开源或闭源的大模型不断涌现,解决一个又一个的应用,填补一个又一个的空白。而在此之前已经有了许多「足够好的」小模型。于是对于用户来说,要找到合适的模型就更加困难... 人工智能# 模型 3年前430
我只会Java一门语言够用吗? 如果你这么想,说明你被自己的看家本事给局限住了,这种思维方式会让你即便学到了更多好东西,也无可奈何。,程序设计语言之间没那么泾渭分明,多学几门才能打破语言局限,让设计更好落地。可根据项目特点选择合适语... 网站建设# 模型# 程序员# 程序设计 3年前430
算力芯片+服务器+数据中心,如何测算ChatGPT算力需求? ChatGPT发布之后,引发了全球范围的关注和讨论,国内各大厂商相继宣布GPT模型开发计划。以GPT模型为代表的AI大模型训练,需要消耗大量算力资源,主要需求场景来自:预训练+日常运营+Finetun... 网站建设# chatgpt# gpt# 模型 5年前430
微调7B模型只用单GPU!通用多模态工具LLaMA-Adapter拆掉门槛,效果惊人 LLaMA-Adapter,现在已经完全解锁了。 作为一个通用的多模态基础模型,它集成了图像、音频、文本、视频和3D点云等各种输入,同时还能提供图像、文本和检测的输出。 相比于之前已经推出的LLaMA... 人工智能# 模型 3年前420
一块GPU跑ChatGPT体量模型,AI绘图又一神器ControlNet 目录 Transformer models: an introduction and catalog High-throughout Generative Inference of Large Lan... 人工智能# 模型 3年前420
GPT-4发布后,其他大模型怎么办?Yann LeCun:增强语言模型或许是条路 ChatGPT、GPT-4 的火爆,让大型语言模型迎来了迄今为止的高光时刻。但下一步又该往何处去? Yann LeCun 最近参与的一项研究指出,增强语言模型或许是个极具潜力的方向。 这是一篇综述文章... 人工智能# 模型 3年前420
首个二值量化评测基准来了,北航/NTU/ETH联合提出,论文登ICML 2023 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 二值量化可以有效节约AI模型消耗的资源。 具体而言,它可以把32位浮点数值压缩到1位,大大降低了存储和运算成本。 然而,此... 人工智能# 模型 3年前420
全面了解大语言模型,这有一份阅读清单 大型语言模型已经引起了公众的注意,短短五年内,Transforme等模型几乎完全改变了自然语言处理领域。此外,它们还开始在计算机视觉和计算生物学等领域引发革命。 鉴于Transformers对每个人的... 人工智能# 模型 3年前420
羊驼系列大模型和ChatGPT差多少?详细测评后,我沉默了 前段时间,谷歌的一份泄密文件引发了广泛关注。在这份文件中,一位谷歌内部的研究人员表达了一个重要观点:谷歌没有护城河,OpenAI 也没有。 这位研究人员表示,虽然表面看起来 OpenAI 和谷歌在 A... 人工智能# 模型 3年前420
Go1.19 那些事:国产芯片、内存模型等新特性,你知道多少? 大家好,我是煎鱼。,感觉时间过得很快,Go1.18 发布没太久,泛型还在风风火火,看了看上次的投票结果,绝大部分同学还没有在生产环境应用泛型。,这不,Go1.19 Beta1 已经正式发布了。今天就由... 网站建设# atomic# go# 内存 4年前420
复杂推理:大语言模型的北极星能力 最近,很多关于较小模型的研究取得了令人振奋的对话能力,这让人们想象,是否较小的模型能具有与像 GPT-3.5 这样的大型模型相当的性能。一般来说,语言模型具有多维能力,所以模型之间的相互对比较为困难... 人工智能# 模型 3年前410
有证据了,MIT表明:大型语言模型≠随机鹦鹉,确实能学到语义 虽然大型预训练语言模型(LLM)在一系列下游任务中展现出飞速提升的性能,但它们是否真的理解其使用和生成的文本语义? 长期以来,AI社区对这一问题存在很大的分歧。有一种猜测是,纯粹基于语言的形式(例如训... 人工智能# 模型 3年前410
顶会是否应该降低接收门槛?用博弈论探索最优审稿和决策机制 近年来,人工智能领域对于大型计算机会议审稿机制的诟病与日俱增,这一切背后的矛盾源于论文作者、会议主办方和审稿人三方并不一致的利益: 论文作者希望他们的论文被会议接收; 会议主办方希望接收更多的优质论文... 人工智能# 模型 3年前410
超越GPT 3.5的小模型来了! 去年年底,OpenAI 向公众推出了 ChatGPT,一经发布,这项技术立即将 AI 驱动的聊天机器人推向了主流话语的中心,众多研究者并就其如何改变商业、教育等展开了一轮又一轮辩论。 随后,科技巨头们... 人工智能# 模型 3年前410
扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术 近年来,多模态学习受到重视,特别是文本 - 图像合成和图像 - 文本对比学习两个方向。一些 AI 模型因在创意图像生成、编辑方面的应用引起了公众的广泛关注,例如 OpenAI 先后推出的文本图像模型 ... 人工智能# 模型 3年前410
机器学习:使用 Python 进行预测 当然,现在我们所有人都知道这个道理了!这篇文章展示了如何将 Python 中开发的机器学习模型作为 Java 代码的一部分来进行预测。,本文假设你熟悉基本的开发技巧并理解机器学习。我们将从训练我们的模... 网站建设# python# 上传# 机器 3年前410
Netty中提供了哪些线程模型? 最近,我更新了一些Netty相关的内容,于是有很多粉丝开始私信问我一些关于Netty的问题。今天,给大家分享一个大家问得比较多问题,Netty中提供了哪些线程模型?,,说到线程模型,又不得不说Nett... 网站建设# netty# reactor# 多线程 5年前410
阿里解马斯克难题?国内首个大模型价值对齐数据集开源,15万评测题上线! 如何让AI和人类的价值观对齐?这个问题,曾经难倒了业界的一众大佬。 OpenAI已经预言,超级智能会在10年内降临。为了不让它失控,OpenAI要组建「超级对齐」(Superalignment)团队... 人工智能# 模型 3年前400
蒸馏也能Step-by-Step:新方法让小模型也能媲美2000倍体量大模型 大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步蒸馏(Distilling Step-by-S... 人工智能# 模型 3年前400
只要模型够大、样本够多,AI就可以变得更智能! AI模型与人脑在数学机制上并没有什么区别。 只要模型够大、样本够多,AI就可以变得更智能! chatGPT的出现,实际上已经证明了这点。 1,AI和人脑的底层细节都是基于if else语句 逻辑运算... 人工智能# 模型 3年前400
小羊驼背后的英雄,伯克利开源LLM推理与服务库:GPU减半、吞吐数十倍猛增 随着大语言模型(LLM)的不断发展,这些模型在很大程度上改变了人类使用 AI 的方式。然而,实际上为这些模型提供服务仍然存在挑战,即使在昂贵的硬件上也可能慢得惊人。 现在这种限制正在被打破。最近,来自... 人工智能# 模型 3年前400
中国人民大学卢志武:ChatGPT对多模态通用生成模型的重要启发 以下为卢志武教授在机器之心举办的 ChatGPT 及大模型技术大会上的演讲内容,机器之心进行了不改变原意的编辑、整理: 大家好,我是中国人民大学卢志武。我今天报告的题目是《ChatGPT 对多模态通用... 人工智能# 模型 3年前400
学会洋葱架构,落地DDD得心应手 领域是一个知识的范畴。它指的是我们的软件所要模拟的业务知识。领域驱动设计的中心是领域模型,它对一个领域的流程和规则有着深刻的理解。洋葱架构实现了这一概念,并极大地改善了代码的品质,降低了复杂性,并且支... 网站建设# 架构# 核心# 模型 4年前400
十个常用的损失函数解释以及Python代码实现 损失函数是一种衡量模型与数据吻合程度的算法。损失函数测量实际测量值和预测值之间差距的一种方式。损失函数的值越高预测就越错误,损失函数值越低则预测越接近真实值。对每个单独的观测(数据点)计算损失函数。将... 网站建设# 函数# 度量# 指标 4年前400
大模型知识Out该怎么办?浙大团队探索大模型参数更新的方法—模型编辑 夕小瑶科技说 原创 作者 | 小戏、Python 大模型在其巨大体量背后蕴藏着一个直观的问题:“大模型应该怎么更新?” 在大模型极其巨大的计算开销下,大模型知识的更新并不是一件简单的“学习任务”,理想... 人工智能# 模型 3年前390
一次10万token!GPT4最强对手史诗升级,百页资料一分钟总结完毕 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 号称ChatGPT“最强竞争对手”的Claude,今天迎来史诗级更新—— 模型记忆力原地起飞,现在1分钟看完一本数万字的小... 人工智能# 模型 3年前390
500万token巨兽,一次读完全套「哈利波特」!比ChatGPT长1000多倍 记性差是目前主流大型语言模型的主要痛点,比如ChatGPT只能输入4096个token(约3000个词),经常聊着聊着就忘了之前说什么了,甚至都不够读一篇短篇小说的。 过短的输入窗口也限制了语言模型的... 人工智能# 模型 3年前390
「多模态LLM」最新介绍!数据、论文集直接打包带走 进展跟踪链接(Awesome-MLLM,实时更新):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models 近年来,大型... 人工智能# 模型 3年前390
连百年梗图都整明白了!微软多模态「宇宙」搞定IQ测试,仅16亿参数 大模型的卷,已经不睡觉都赶不上进度了...... 这不,微软亚研院刚刚发布了一个多模态大型语言模型(MLLM)—— KOSMOS-1。 论文地址:https://arxiv.org/pdf/2302... 人工智能# 模型 3年前390
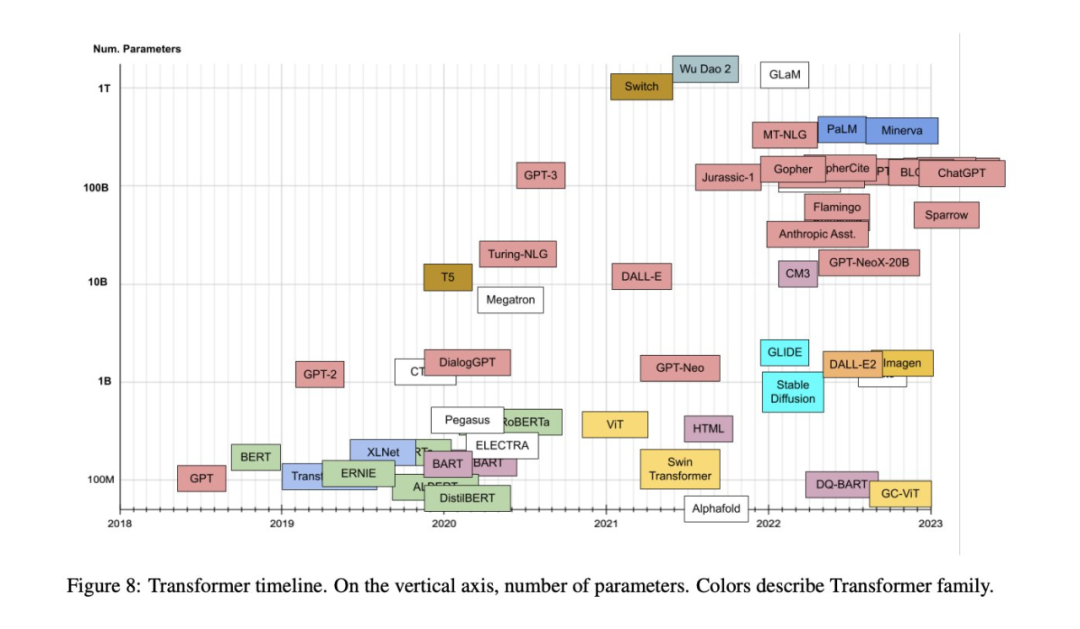
20+篇里程碑式论文,带你从「Transformer的前世」速通到ChatGPT 短短五年,Transformer就几乎颠覆了整个自然语言处理领域的研究范式,是划时代产品ChatGPT的基础技术,也促进了计算机视觉、计算生物学等领域的研究进展。 在发展的过程中,研究人员发表了大量论... 人工智能# 模型 3年前390
人手AutoGPT!让ChatGPT自选10万+AI模型,HuggingFace官方出品 前段时间,浙大微软团队提出的HuggingGPT在整个科技圈爆火。 这个大模型协作系统利用ChatGPT作为控制器,随意调用HuggingFace中的各种模型,以实现多模态任务。 让ChatGPT当... 人工智能# 模型 3年前390
面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能 阿里云机器学习平台PAI与华东师范大学高明教授团队合作在SIGIR2022上发表了结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于... 人工智能# 模型 3年前390
马腾宇团队新出大模型预训练优化器,比Adam快2倍,成本减半 鉴于语言模型预训练成本巨大,因而研究者一直在寻找减少训练时间和成本的新方向。Adam 及其变体多年来一直被奉为最先进的优化器,但其会产生过多的开销。本文提出了一种简单的可扩展的二阶优化器 Sophia... 人工智能# 模型 3年前380
放弃RLHF吧!无需手动训练模型价值观,达特茅斯学院华人领衔发布全新对齐算法:「AI社会」是最好的老师 训练大型语言模型的最后一步就是「对齐」(alignment),以确保模型的行为符合既定的人类社会价值观。 相比人类通过「社交互动」获得价值判断共识,当下语言模型更多的是孤立地从训练语料库中学习价值观... 人工智能# 模型 3年前380
UC伯克利发布大语言模型排行榜!Vicuna夺冠,清华ChatGLM进前5 最近,来自LMSYS Org(UC伯克利主导)的研究人员又搞了个大新闻——大语言模型版排位赛! 顾名思义,「LLM排位赛」就是让一群大语言模型随机进行battle,并根据它们的Elo得分进行排名。 然... 人工智能# 模型 3年前380
AI绘画侵权实锤!扩散模型可能记住你的照片,现有隐私保护方法全部失效 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 AI绘画侵权,实锤了! 最新研究表明,扩散模型会牢牢记住训练集中的样本,并在生成时“依葫芦画瓢”。 也就是说,像Stabl... 人工智能# 模型 3年前380
基于T5的两阶段的多任务Text-to-SQL预训练模型MIGA 越来越多的工作证明了预训练语言模型(PLM)中蕴含着丰富的知识,针对不同的任务,用合适的训练方式来撬动 PLM,能更好地提升模型的能力。在 Text-to-SQL 任务中,目前主流的生成器是基于语法树... 人工智能# 模型 3年前380
一句话让三维模型生成逼真外观风格,精细到照片级细节 根据给定输入创建 3D 内容(例如,根据文本提示、图像或 3D 形状)在计算机视觉和图形领域具有重要应用。然而这个问题是具有挑战性的,现实中通常需要专业艺术家(Technical Artist)耗费大... 人工智能# 模型 3年前380
权限系统就该这么设计,yyds 这篇文章就来解答介绍一下权限系统的设计以及主流的五种权限模型。,权限管控可以通俗的理解为权力限制,即不同的人由于拥有不同权力,他所看到的、能使用的可能不一样。对应到一个应用系统,其实就是一个用户可能拥... 网站建设# acl# 列表# 客体 4年前380
不到1000步微调,将LLaMA上下文扩展到32K,田渊栋团队最新研究 在大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重要评估指标。 比如 OpenAI 的 gpt-3.5-turbo 提供 16k token 的上下文窗口选项... 人工智能# 模型 3年前370
哈工大南洋理工提出全球首个「多模态DeepFake检测定位」模型:让AIGC伪造无处可藏 由于如Stable Diffusion等视觉生成模型的快速发展,高保真度的人脸图片可以自动化地伪造,制造越来越严重的DeepFake问题。 随着如ChatGPT等大型语言模型的出现,大量假本文也可以容... 人工智能# 模型 3年前370
ChatGPT自己会选模型了!微软亚研院+浙大爆火新论文,HuggingGPT项目已开源 ChatGPT引爆的AI热潮也「烧到了」金融圈。 近来,彭博社的研究人员也开发了一个金融领域的GPT——Bloomberg GPT,有500亿参数。 GPT-4的横空出世,让许多人浅尝到了大型语言模型... 人工智能# 模型 3年前370
AI「黑箱」被打开?谷歌找到大模型能力涌现机制 前段时间,OpenAI整出了神操作,竟让GPT-4去解释GPT-2的行为。 对于大型语言模型展现出的涌现能力,其具体的运作方式,就像一个黑箱,无人知晓。 众所周知,语言模型近来取得巨大的进步,部分原因... 人工智能# 模型 3年前370
华人科学团队推出「思维链集」,全面测评大模型复杂推理能力 大模型能力涌现,参数规模越大越好? 然而,越来越多的研究人员声称,小于10B的模型也可以实现与GPT-3.5相当的性能。 真是如此吗? OpenAI发布GPT-4的博客中,曾提到: 在随意的交谈中,G... 人工智能# 模型 3年前370
物理改变图像生成:扩散模型启发于热力学,比它速度快10倍的挑战者来自电动力学 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 现在,图像生成领域的半壁江山已经被物理学拿下了。 火出圈的DALL·E 2、Imagen和Stable Diffusion... 人工智能# 模型 3年前370
Transformer结构及其应用详解——GPT、BERT、MT-DNN、GPT-2 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理... 人工智能# 模型 3年前360
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75% 前些天,OpenAI 的 CEO Sam Altman 在全球巡回演讲中,透漏了 OpenAI 近期发展路线,主要分两个阶段,2023 年的首要任务是推出更便宜、更快的 GPT-4,更长的上下文窗口等... 人工智能# 模型 3年前360
谷歌复用30年前经典算法,CV引入强化学习,网友:视觉RLHF要来了? ChatGPT 的火爆有目共睹,而对于支撑其成功背后的技术,监督式的指令微调以及基于人类反馈的强化学习至关重要。这些技术也在逐渐扩展到其他 AI 领域,包括计算机视觉(CV)。 我们知道,在处理计算... 人工智能# 模型 3年前360
多模态可控图片生成统一模型来了,模型参数、推理代码全部开源 论文地址:https://arxiv.org/abs/2305.11147 代码地址:https://github.com/salesforce/UniControl 项目主页:https://sho... 人工智能# 模型 3年前360
MiniGPT-4看图聊天、还能草图建网站;视频版Stable Diffusion来了 目录 Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models MiniGPT-4:Enhan... 人工智能# 模型 3年前360
英伟达超快StyleGAN回归,比Stable Diffusion快30多倍,网友:GAN好像只剩下快了 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 扩散模型的图像生成统治地位,终于要被GAN夺回了? 就在大伙儿喜迎新年之际,英伟达一群科学家悄悄给StyleGAN系列做了... 人工智能# 模型 3年前360
惊呆了!我用 Python 可视化分析和预测了 2022 年 FIFA 世界杯 许多人称足球为 "不可预测的游戏",因为一场足球比赛有太多不同的因素可以改变最后的比分。,从某种程度上这是真的.....因此本文仅供学习参考!!,预测一场比赛的最终比分或赢家确实是很难的,但在预测一项... 网站建设# 模型# 比分# 比赛 4年前360
「成熟」大模型才能涌现?MIT:GPT-4能自我纠错代码,GPT-3.5却不行 我们都知道,大语言模型在生成代码方面,表现出了非凡的能力。然而,在具有挑战性的编程任务(比如竞赛和软件工程师的面试)中,它们却完成得并不好。 好在,很多模型会通过一种自修复工作流来「自省」,来自我纠正... 人工智能# 模型 3年前350
视觉AI能力大一统!自动化图像检测分割,还能可控文生图,华人团队出品 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 现在AI圈确实到了拼手速的时候啊。 这不,Meta的SAM刚刚推出几天,就有国内程序猿来了波buff叠加,把目标检测、分割... 人工智能# 模型 3年前350
用BT下载的方式在家跑千亿大模型,推理/微调速度10倍提升 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 在家用消费级GPU就能跑1760亿参数大模型,推理微调都很快。 还是用BT下载的方式实现。 这事儿可把AI爱好者们新鲜坏了... 人工智能# 模型 3年前350
一个模型解决两种模态,谷歌AudioPaLM一统「文本+音频」:能说还能听的大模型 大型语言模型以其强大的性能及通用性,带动了一批多模态的大模型开发,如音频、视频等。 语言模型的底层架构大多是基于Transformer,且以解码器为主,所以无需过多调整模型架构即可适应其他序列模态。 ... 人工智能# 模型 3年前350
你的AI模型可能有后门!图灵奖得主发53页长文:小心恶意预测 「对抗样本」是一个老生常谈的问题了。,在一个正常的数据中,加入一些轻微扰动,比如修改图片中的几个像素,人眼不会受影响,但AI模型的预测结果可能会发生大幅变化。,对于这种bad case,目前来说还是... 网站建设# ai# 后门# 模型 5年前350
OpenAI联合创始人亲自上场科普GPT,让技术小白也能理解最强AI 在近日举办的微软开发者大会 Microsoft Build 2023 上,OpenAI 联合创始人 Andrej Karpathy 做了一个题为《State of GPT》演讲,其中他首先直观地介绍了... 人工智能# 模型 3年前340
理解指向,说出坐标,Shikra开启多模态大模型参考对话新维度 在人类的日常交流中,经常会关注场景中不同的区域或物体,人们可以通过说话并指向这些区域来进行高效的信息交换。这种交互模式被称为参考对话(Referential Dialogue)。 如果 MLLM 擅长... 人工智能# 模型 3年前340
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了 大模型的发展可谓一日千里,指令微调方法犹如雨后春笋般涌现,大量所谓的 ChatGPT “平替” 大模型相继发布。在大模型的训练与应用开发中,开源、闭源以及自研等各类大模型真实能力的评测已经成为提高研发... 人工智能# 模型 3年前340
13948道题目,涵盖微积分、线代等52个学科,上交清华给中文大模型做了个测试集 ChatGPT 的出现,使中文社区意识到与国际领先水平的差距。近期,中文大模型研发如火如荼,但中文评价基准却很少。 在 OpenAI GPT 系列 / Google PaLM 系列 / DeepMin... 人工智能# 模型 3年前340
无需注意力的预训练;被GPT带飞的In-Context Learning 论文 1:ClimateNeRF: Physically-based Neural Rendering for Extreme Climate Synthesis 作者:Yuan Li等 论文地址:h... 人工智能# 模型 3年前340
移除ImageNet标签错误,模型排名发生大变化 此前,ImageNet 因为存在标签错误的问题而成为热门话题,这个数字说出来你可能会大吃一惊,至少有十万个标签是存在问题的。那些基于错误标签做的研究,很可能要推翻重来一遍。 由此看来管理数据集质量还是... 人工智能# 模型 3年前340
人人都能用的多语种大语言模型来了!支持59种语言,参数1760亿 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 一直以来,很多大模型都由造它们出来的大型私营科技公司垄断着。 比如GPT-3等,对于普通人来说,再香也只能眼巴巴看着。 不... 人工智能# 模型 3年前340
这个模型,让前特斯拉AI总监Andrej Karpathy沉迷了整整三天! 最近,一个叫Xander Steenbrugge的AI研究员兼数码艺术家,上传了一段非常震撼的视频《跨越时间之旅》。 地球上的生物大进化,从原始海洋起始,到远古蜥蜴、恐龙、哺乳动物,再到猴子、猩猩、猿... 人工智能# 模型 3年前340
其他人还在放“大模型”的卫星 微软已经教会开发者怎么用它了 春夏之交,正是全球各大顶级科技公司举办年度活动的季节。两周前是谷歌,而这一周终于轮到了微软。仅用短短43分钟的时间,微软董事长兼 CEO 萨蒂亚·纳德拉 (Satya Nadella) 就完成了今年 ... 网站建设# ceo# 发布# 开发者 4年前340
供应链时效域接口性能进阶之路 供应链时效域历经近一年的发展,在预估时效方面沉淀出了一套理论和两把利器(预估模型和路由系统)。以现货为例,通过持续的技术方案升级,预估模型的准确率最高接近了90%,具备了透出给用户的条件。但在接入前台... 网站建设# 供应链# 失效# 接口 5年前340
大型语言模型与知识图谱协同研究综述:两大技术优势互补 大型语言模型(LLM)已经很强了,但还可以更强。通过结合知识图谱,LLM 有望解决缺乏事实知识、幻觉和可解释性等诸多问题;而反过来 LLM 也能助益知识图谱,让其具备强大的文本和语言理解能力。而如果能... 人工智能# 模型 3年前330
ChatGPT平替「小羊驼」Mac可跑!2行代码单GPU,UC伯克利再发70亿参数开源模型 自从Meta发布「开源版ChatGPT」LLaMA之后,学界可谓是一片狂欢。 先是斯坦福提出了70亿参数Alpaca,紧接着又是UC伯克利联手CMU、斯坦福、UCSD和MBZUAI发布的130亿参数V... 人工智能# 模型 3年前330
思维链如何释放语言模型的隐藏能力?最新理论研究揭示其背后奥秘 思维链提示(CoT)是大模型涌现中最神秘的现象之一,尤其在解决数学推理和决策问题中取得了惊艳效果。CoT到底有多重要呢?它背后成功的机制是什么?本文中,北大的几位研究者证明了CoT在实现大语言模型(L... 人工智能# 模型 3年前330
上海数字大脑研究院发布国内首个多模态决策大模型DB1,可实现超复杂问题快速决策 近日,上海数字大脑研究院(以下简称 “数研院”)推出首个数字大脑多模态决策大模型(简称 DB1),填补了国内在此方面的空白,进一步验证了预训练模型在文本、图 - 文、强化学习决策、运筹优化决策方面应用... 人工智能# 模型 3年前330
参数减半、与CLIP一样好,视觉Transformer从像素入手实现图像文本统一 近年来,基于 Transformer 的大规模多模态训练促成了不同领域最新技术的改进,包括视觉、语言和音频。特别是在计算机视觉和图像语言理解方面,单个预训练大模型可以优于特定任务的专家模型。 然而,大... 人工智能# 模型 3年前330
资源受限如何提高模型效率?一文梳理NLP高效方法 训练越来越大的深度学习模型已经成为过去十年的一个新兴趋势。如下图所示,模型参数量的不断增加让神经网络的性能越来越好,也产生了一些新的研究方向,但模型的问题也越来越多。 首先,这类模型往往有访问限制,没... 人工智能# 模型 3年前330
自己做一个ChatGPT微信小程序(代码开源) 离职在家 闲来无事看最近ChatGPT很火 花了一天时间 用Uniapp写了一个小程序端的ChatGPT,实在是看不惯~ 一大堆利用ChatGPT收费的应用(小程序) 整个开源的玩玩 另外主要是自己本... 网站建设# ai# chatgpt# uniapp 5年前330
在Transformer时代重塑RNN,RWKV将非Transformer架构扩展到数百亿参数 Transformer 模型在几乎所有自然语言处理(NLP)任务中都带来了革命,但其在序列长度上的内存和计算复杂性呈二次方增长。相比之下,循环神经网络(RNNs)在内存和计算需求上呈线性增长,但由于并... 人工智能# 模型 3年前320
OpenAI文本生成3D模型再升级,数秒完成建模,比Point·E更好用 生成式 AI 大模型是 OpenAI 发力的重点,目前已经推出过文本生成图像模型 DALL-E 和 DALL-E 2,以及今年初基于文本生成 3D 模型的 POINT-E。 近日,OpenAI 研究团... 人工智能# 模型 3年前320
Meta千亿参数大模型OPT-IML「升级版」来了,完整模型和代码公布! 今年五月,MetaAI官宣发布了基于1750亿参数的超大模型OPT-175B,还对所有社区免费开放。 12月22日,该模型的更新版本OPT-IML(Open Pre-trained Transform... 人工智能# 模型 3年前320
被GPT带飞的In-Context Learning为什么起作用?模型在秘密执行梯度下降 继 BERT 之后,研究者们注意到了大规模预训练模型的潜力,不同的预训练任务、模型架构、训练策略等被提出。但 BERT 类模型通常存在两大缺点:一是过分依赖有标签数据;二是存在过拟合现象。 具体而言... 人工智能# 模型 3年前320
YOLOv7速度精度超越其他变体,大神AB发推,网友:还得是你 本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。 前脚美团刚发布YOLOv6, YOLO官方团队又放出新版本。 曾参与YOLO项目维护的大神Alexey Bochkovsk... 人工智能# 模型 3年前320
关注点和热点揭秘!大模型用于企业数据开发详解! 点击参加51CTO网站内容调查问卷 作者 | Sam Stone 译者 | 朱先忠 审校 | 重楼 什么?要求GPT-4在提示语押韵的同时,证明存在无穷多的素数,那么它的确能够实现(https://a... 人工智能# 模型 3年前310
DeepSpeed ZeRO++:降低4倍网络通信,显著提高大模型及类ChatGPT模型训练效率 大型 AI 模型正在改变数字世界。基于大型语言模型 (LLM) 的 Turing-NLG、ChatGPT 和 GPT-4 等生成语言模型用途广泛,能够执行摘要、代码生成和翻译等任务。同样,DALL・E... 人工智能# 模型 3年前310
UC伯克利LLM准中文排行榜来了!GPT-4稳居第一,国人开源RNN模型冲进前六 前段时间,来自LMSYS Org(UC伯克利主导)的研究人员搞了个大新闻——大语言模型版排位赛! 这次,团队不仅带来了4位新玩家,而且还有一个(准)中文排行榜。 OpenAI GPT-4 OpenAI... 人工智能# 模型 3年前310
微软多模态ChatGPT来了?16亿参数搞定看图答题、智商测验等任务 在 NLP 领域,大型语言模型(LLM)已经成功地在各种自然语言任务中充当通用接口。只要我们能够将输入和输出转换为文本,就能使得基于 LLM 的接口适应一个任务。举例而言,摘要任务输入文档,输出摘要信... 人工智能# 模型 3年前310
初探AI拼图模型预测蛋白质复合物结构 分子表示学习在 AI 辅助药物发现研究中起着至关重要的作用。在传统药物研发中,常用的分子对接模型需要进行大量的构型采样与优化,并筛选出较为稳定的结构。这类策略效率较低,难以应用于高通量的蛋白质对接任务... 人工智能# 模型 3年前310
首个ChatGPT国产平替来了!ChatYuan发布测试版,无需注册,体验完全免费 还在想方设法注册体验ChatGPT吗?不用那么麻烦了! 中文NLP社区也迎来了自己的ChatGPT,最近元语智能开发团队训练了一个叫做元语AI(ChatYuan)的模型,它通过对话形式进行交互:可以回... 人工智能# 模型 3年前310
大模型如何可靠?IBM等学者最新《基础模型的基础鲁棒性》教程 作为当前全球最负盛名的 AI 学术会议之一,NeurIPS 是每年学界的重要事件,全称是 Neural Information Processing Systems,神经信息处理系统大会,通常在每年 ... 人工智能# 模型 3年前310
30年历史回顾,Jeff Dean:我们整理了一份「稀疏专家模型」研究综述 稀疏专家模型是一个已有 30 年历史的概念,至今依然被广泛使用,是深度学习中的流行架构。此类架构包括混合专家系统(MoE)、Switch Transformer、路由网络、BASE 层等。稀疏专家模型... 人工智能# 模型 3年前310
微软新工具准确率达80%,程序员:真的栓 Q 微软宣布推出一种可以提高大型语言模型性能的新工具 Jigsaw。“大型的预训练语言模型(如 GPT-3、Codex 等),可以被调整为从程序员意图的自然语言规范中生成代码。这种自动化模型有可能提高世界... 网站建设# jigsaw# pandas# 微软 4年前310
python线性规划问题的处理步骤 ,说明,1、问题定义,确定决策变量、目标函数和约束条件。,2、模型构建,由问题描述建立数学方程,转化为标准形式的数学模型。,3、模型求解,用标准模型的优化算法对模型进行求解,得到优化结果。,实例,不等... 网站建设# python# 教程# 模型 5年前310
李志飞:关于GPT-4的八点观察,多模态大模型竞赛开始 自微软3月初发布多模态模型 Kosmos-1 以来,一直在测试和调整 OpenAI 的多模态模型,并将其更好地兼容微软自有产品。 果不其然,趁着GPT-4发布之际,微软也正式摊牌,New Bing早就... 人工智能# 模型 3年前300
模型越大,表现越差?谷歌收集了让大模型折戟的任务,还打造了一个新基准 随着语言模型变得越来越大(参数数量、使用的计算量和数据集大小都变大),它们的表现似乎也原来越好,这被称为自然语言的 Scaling Law。这一点已经在很多任务中被证明是正确的。 或许,也存在某些任务... 人工智能# 模型 3年前300
DALL-E和Flamingo能相互理解吗?三个预训练SOTA神经网络统一图像和文本 多模态研究的一个重要目标就是提高机器对于图像和文本的理解能力。特别是针对如何在两种模型之间实现有意义的交流,研究者们付出了巨大努力。举例来说,图像描述(image captioning)生成应当能将图... 人工智能# 模型 3年前300